论文笔记 - Towards High Performance Video Object Detection for Mobiles
前言
这是MSRA代季峰组在视频检测的又一篇文章,也是这一系列的第四篇文章,主要是将前三篇的工作进行了轻量化,将神经网络和算法记性了调整,部署在移动平台上。在华为Mate 8上,算法的运行速度为25.6FPS,准确率为60.2%。
论文:Towards High Performance Video Object Detection for Mobiles
背景
视频目标检测的框架:
Sparse Feature Propagation: 在关键帧上计算feature map,在非关键帧上通过Flow将feature map进行传播。
Multi-frame feature aggregation : 将多帧feature map进行聚合,提高特征的质量和检测准确率。
但是在移动平台上,由于Flow的计算远远达不到实时计算的要求,并且多帧feature map的聚合也要受到手机有限内存的限制
主要贡献
本论文提出了一种适用于手机端视频目标检测的轻量级神经网络。该网络在遵循上述两个原则的前提下,对网络进行了精心的设计:
- 首先在所有帧上都使用了Light Flow,一个轻量级的用于计算光流的网络。
- 在少数关键帧上,作者提出了Flow-guided Gated Recurrent Unit based Feature Aggregation,它可以在内存有限的平台上进行特征的聚合。
- 在目标检测方面,作者使用了一个轻量的目标检测网络,使用了depthwise separable convolution以及Light-Head R-CNN,可以在关键帧上计算Feature map。
回顾
在图像上的目标检测可以分为两个部分:
特征网络 :通过卷积神经网络从图片中提取一系列Feature Map,这部分可以表示为:
$$ N_{feat}(I)=F $$
检测网络:通过在feature map上稀疏的proposals或者在密集的滑动窗口中,进行region classification和bounding box regressi来产生检测结果,这办法可以表示为:
$$ N_{det}(F) = y $$
但是,直接将这样的算法流程套用到视频目标检测中,会出现一些问题。在速度方面,由于特征网络通常比较深,计算速度较慢,直接在视频的每一帧上使用检测器的效率太低;此外,视频中还存在一些运动模糊、视频失焦等图像中不存在的问题。
因此,现在的视频图像识别采用的方法多为Sparse Feature Propagation和Multi-frame feature aggregation相结合的方式。
Sparse Feature Propagation : 由于视频中相邻帧之间包含冗余信息,因此不需要再每一帧中提取feature map。Deep Feature Flow这篇论文提供一个有效的算法,即在少数关键帧(比如每隔10帧)中提取feature map,然后将这些feature map传播到其他非关键帧上,这样的话,可以在牺牲少量精度的情况下,对检测器进行加速。 特征的传播过程可以表示为:
$$ F_{k \rightarrow i} = \mathcal{W}(F_k,M_{i \rightarrow k}) $$
其中F是第k个关键帧中的Feature Map,W代表双线性插值函数,M代表运动场,可以通过计算第i帧和第k帧之间的光流得到(复杂度比提取Feature要容易)。
Multi-frame Feature Aggregation : 为了提高检测精度,FGFA将临近帧的Feature Map聚合起来,公式如下所示:
$$ \hat{F}i = \sum{k \in [i - r,i + r ]} W_{k \rightarrow i} \odot F_{k \rightarrow i} $$
为了防止在每一帧上进行聚合使得计算负担增加,只需要在少数关键帧上进行聚合操作即可,即给定两个关键帧k1,k2,按照如下方式进行聚合:
$$ \hat{F}{k2} = W{k1 \rightarrow k2} \odot \hat{F}{k1 \rightarrow k2} + W{k2 \rightarrow k2} \odot F_{k2} $$
在移动平台上的准则
- 特征提取和聚合只能在少数关键帧上进行
- 光流是特征传播和聚合的关键,因此提取光流的特征需要尽可能轻量级 - 特征聚合需要在临近帧上进行,以此来对抗大型物体的移动
- 特征检测的网络要尽可能的小
移动端网络模型
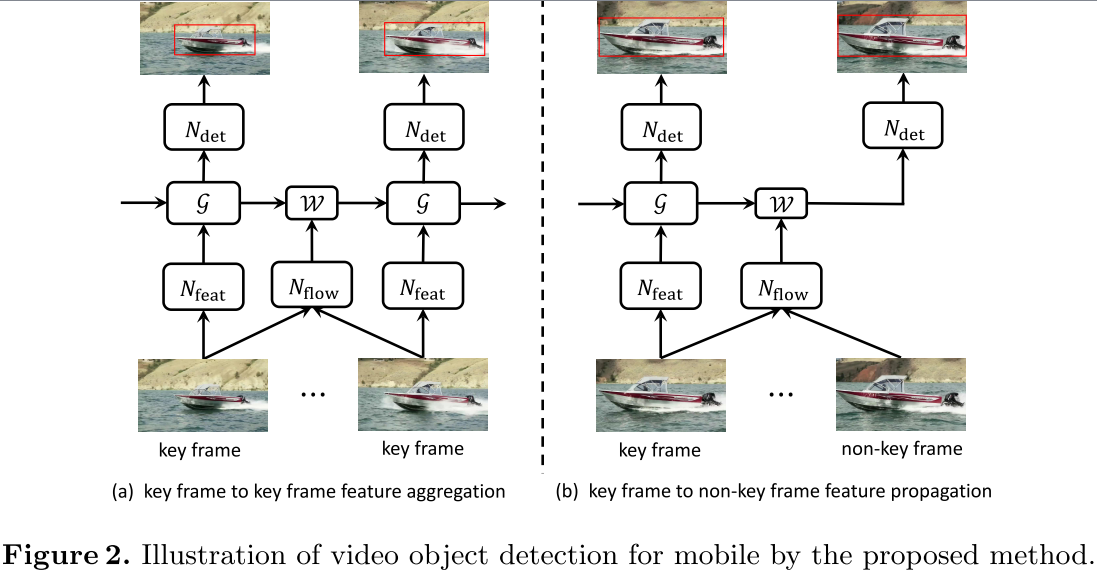 Pipeline
Pipeline
如图所示,可以将算法流程分为两部分:
关键帧 : 假设当前关键帧为k1,之前的关键帧为k2,那么当前帧中的特征可以表示为:
$$ \hat{F}{k1} =\mathcal{G}(F{k1},\hat{F}{k2}, M{k1 \rightarrow k2}) $$
其中,G为光流指导的聚合函数,检测网络直接在上式得到的Feature Map上进行检测。
非关键帧: 假设当前非关键为i,之前的关键帧为k,那么当前帧的特征可以表示为:
$$ \hat{F}{k \rightarrow i} =\mathcal{W}(F{k}, M_{i \rightarrow k}) $$
其中,W为双线性插值函数。
Light Flow
传统的FlowNet分为Encoder,Decoder以及Output三部分,作者对着三部分分别进行了改进。在Encoder部分,把3x3的卷积层替换为了depth-wise卷积层。在Decode部分,将反卷积层替换为了最近邻采样层和depth-wise卷积层的级联。在Output部分,FlowNet是将Encoder和Decoder不同层级的级联输出中挑选最好的,作者直接将这些结果上采样到同一分辨率后,进行平均。
在Flying Chairs数据集上训练完Light Flow后,作者在使用是又使用了两个trick进行加速。Light Flow的输入尺寸被设计为图像size的一半大小,得到光流图后,再将其降采样的和特征网络提取的Feature Map一样大小。此外,Feature Map的传播是在检测网络的中间部分进行的,而不是计算到最后。
Flow-guided GRU based Feature Aggregation
FGFA只能进行短时段的特征聚合,进行长时聚合可能造成类似梯度爆炸或者梯度消失的问题,因此作者引入了GRU来解决特征的长时聚合问题,公式如下所示:
$$ \hat{F}{k1} = \mathcal{G}(F{k1},\hat{F}{k2}, M{k1 \rightarrow k2}) $$
$$ \hat{F}{k1} = (1-z_t) \odot \hat{F}_{k2 \rightarrow k1} + z_t\odot \phi(W_h\star F{k1}+U_h\star(r_t\odot\hat{F}_{k2 \rightarrow k1})+b_h) $$
其中,z为Update Gate,r为Reset Gate:
$$ z_t = \sigma(W_z \star F_{k1}+U_z \star \hat{F}_{k2 \rightarrow k1} + b_z) $$
$$ r_t = \sigma(W_r \star F_{k1}+U_r \star \hat{F}_{k2 \rightarrow k1} + b_r) $$
其中,星号为3x3卷积,sigma为sigmoid函数,phi为ReLU 与传统的GRU相比,主要有三点不同:
- 用3x3卷积代替全卷积层。
- 用ReLu代替Tanget作为激活函数。
- GRU只在关键帧上使用,因此需要考虑位移的影响,所以公式中包含有位移。
Lightweight Key-frame objdect Detector
在特征提取部分,作者使用了MobileNet,在检测部分,作者使用了RPN以及Light-Head R-CNN。
Feature Network : 移除了average pooling和全卷机层,在顶层的feature map上,首先通过3x3的卷积层降低通道维数,然后通过最近邻采样层进行上采样,然后通过一个1X1的卷积层构成的旁路后与原feature map相加。
Detection Network : 使用了RPN和Light-Head R-CNN。
端到端训练
在训练过程中,所有的网络联合训练,输入为n+1帧关键帧,每个关键帧之间距离都为10帧,然后通过SGD进行训练。
实验结果
在实验中,作者使用了VID和ImageNet DET来训练网络,DET中的图片被拷贝成n+1帧,作为一个静态视频进行训练,最终在VID上得到的实验结果如下图所示,在华为Mate 8上,算法的运行速度为25.6FPS,准确率为60.2%。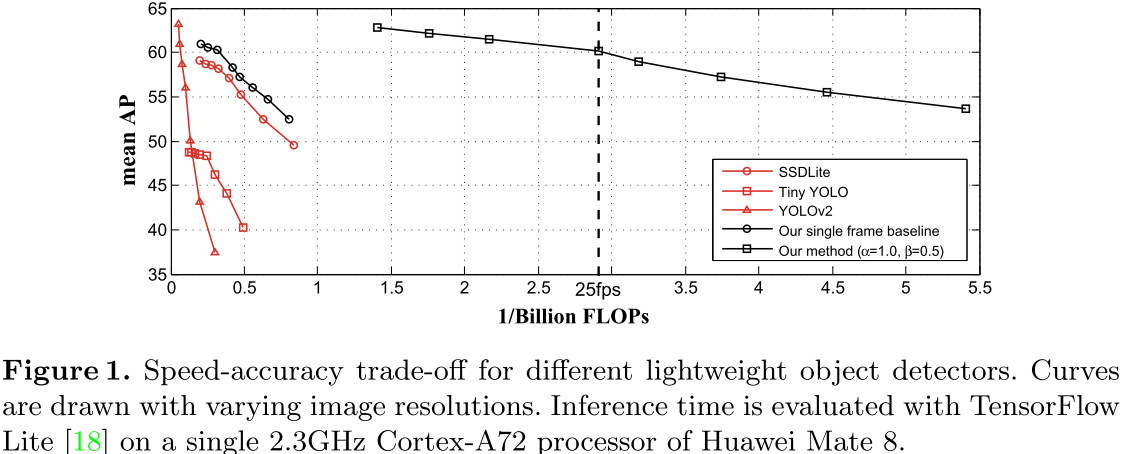 Performance
Performance