论文笔记 - DenseCLIP: Language-Guided Dense Prediction with Context-Aware Prompting
前言
使用大规模文本-图片对进行对比学习训练(CLIP)的方法发展很快,也给下游任务提供了一个很好的模型,但是对于分割任务而言,由于其需要产生pixel级别的密集预测,因此,如何将通过文本-图片对级别训练得到的先验迁移到文本-像素级别的模型上,就成了一个值得研究的问题,为此,本文提出了一种一种将CLIP权重迁移到图像分割模型上的finetune方法。通过进一步从图像中获得背景信息,可以进一步改善CLIP的文本编码器,从而提高模型性能。本文提出的finetune方法可以用于任意图像分割模型,并取得性能提升。
论文:DenseCLIP: Language-Guided Dense Prediction with Context-Aware Prompting
代码:DenseCLIP
背景
CLIP是最近发展起来的一种新的方法,该方法可以从大量的图片-文本对中,通过对比学习得到高质量的视觉特征表达,帮助下游任务取得更好的表现。但对于分割来说,由于需要逐像素预测,即文本-像素级的预测,而CLIP的文本描述和图像内容都是instance级别的,这之间有较大gap,因此直接使用CLIP进行finetune无法充分利用CLIP的性能。本文主要解如何将CLIP的预训练模型迁移到密集预测的任务上去的问题。此外,Prompt Engineering最近在NLP中有了很大发展,对于使用固定文本模板(a photo of a [CLS])的CLIP来说,可以通过改善prompt来提高模型性能。
框架
本文的主要框架如下所示

Language-Guided Dense Prediction
在CLIP方法中,得到ResNet最后一层的特征$\mathbf{x}_4 \in \mathbb{R}^{H_4 W_4 \times C}$ 后,首先使用全局平均得到一个全局图像特征$ \mathbf{x}_4 \in \mathbb{R}^{1 \times C}$,然后将二者concat起来,通过一个MHSA得到自相关后的特征:
$$
[\overline{\mathbf{z}}, \mathbf{z}]=\operatorname{MHSA}\left(\left[\overline{\mathbf{x}}_4, \mathbf{x}_4\right]\right)
$$
$\overline{\mathbf{z}}$ 作为图像特征输出与文本特征进行匹配,而$\mathbf{z}$则被忽略,但是作者发现:
- $\mathbf{z}$仍然保留有效的空间信息,可以作为feature map使用
- $\mathbf{z}$和文本特征也有很好的相关性
文本特征是由固定的文本模板(a photo of a [CLS])输入text encoder编码得到的,$ \mathbf{t} \in \mathbb{R}^{K \times C}$,与图像特征各自经过归一化后即可计算文本-图像的score map(这里的文本特征类似1x1的卷积核):
$$
\mathbf{s}=\hat{\mathbf{z}}^{\top}, \quad \mathbf{s} \in \mathbb{R}^{H_4 W_4 \times K}
$$
得到score map后,可以直接和GT求loss,也可以和最后一层的feature map进行concat后,输入到正常的图像分割后处理网络中得到分割map,再与GT求Loss。
该score map可以用于检测等
Context-Aware Prompting
本文使用可学习的文本feature代替CLIP中通过人为设定模板得到的feature,即输入text encoder的内容为
$$
[\mathbf{p},\mathbf{e}_k],1<k<K
$$
其中$\mathbf{p} \in \mathbb{R}^{N \times K}$为可学习的文本上下文信息,$\mathbf{e}_k \in \mathbb{R}^{C}$为第$k$个类的embedding
除此之外,本文尝试使用图像信息来进一步提升文本feature,并提出了2种可能的做法:
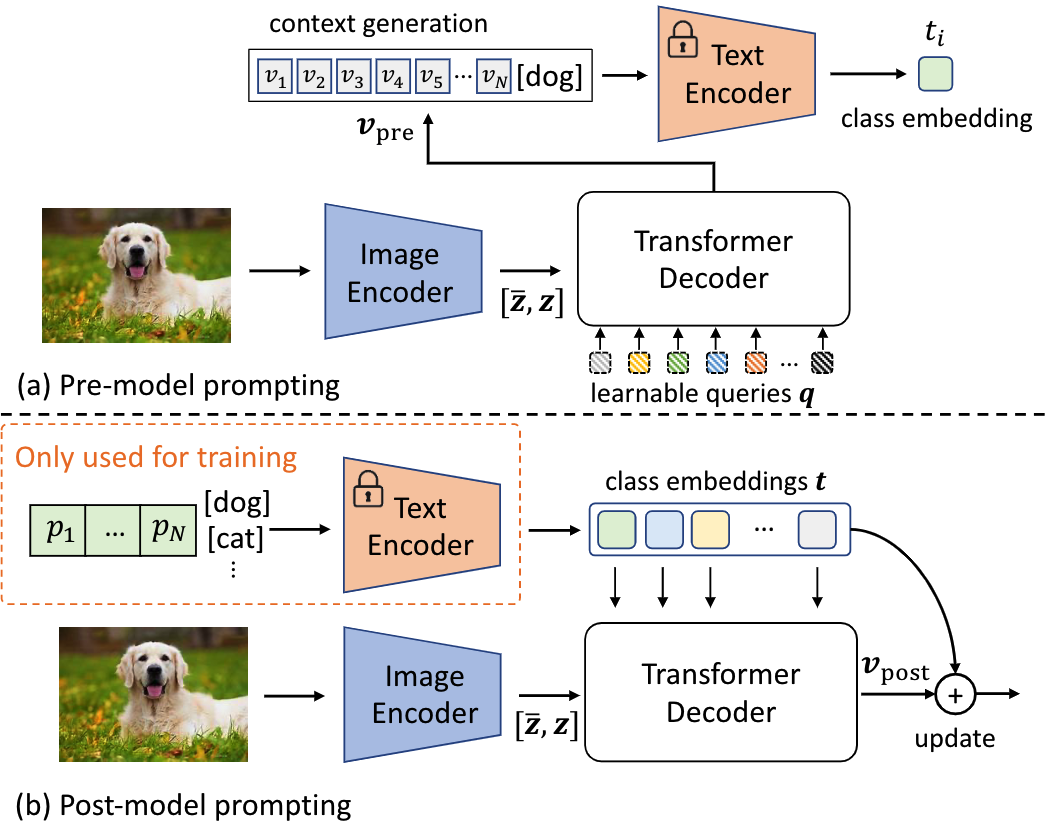
pre-model prompting:先使用query通过transformer decoder从图像特征中得到视觉上下文$v$,然后用$v$替换上个公式中的$\mathbf{p}$,经过text encoder得到文本特征。
$$
\mathbf{v}{pre} = \text{TransDecoder}(\mathbf{q},[\overline{\mathbf{z}}, \mathbf{z}])
$$
post-model prompting:使用text encoder得到的文本特征作为query,通过transformer decoder从图像中得到上下文,经过加权后通过残差连接和原文本特征相加,作为最后的文本特征
$$
\mathbf{v}{post} = \text{TransDecoder}(\mathbf{t},[\overline{\mathbf{z}}, \mathbf{z}]) \
\mathbf{t} \leftarrow \mathbf{t}+\gamma \mathbf{v}_{\text {post }}
$$
经过比较,作者更倾向于post-model prompting,因为:
- 更加高效,在推理阶段,pre-model prompting的text encoder输入依赖于图像特征。而post-model prompting可以将最初的文本特征保存下来,就不需要一直使用text encoder进行计算了
- 实验显示post-model prompting更加有效
Instantiations
语义分割:因为$\mathbf{s} \in \mathbb{R}^{H_4 W_4 \times K}$可以被视为分割结果,因此可以直接对score map进行监督,其中$\tau=0.07$,$\mathbf{y} \in{1, \ldots, K}^{H_4 W_4}$为GT
$$
\mathcal{L}{\mathrm{aux}}^{\mathrm{seg}}=\operatorname{CrossEntropy}(\operatorname{Softmax}(\mathbf{s} / \tau), \mathbf{y})
$$
检测和实例分割:可以通过bounding box以及标签构建一个二值化的GT,$\tilde{\mathbf{y}} \in{0,1}^{H_4 W_4 \times K}$,用来求辅助loss
$$
\mathcal{L}{\mathrm{aux}}^{\text {det }}=\text { BinaryCrossEntropy }(\operatorname{Sigmoid}(\mathbf{s} / \tau), \tilde{\mathbf{y}})
$$
对于任务模型适用:将CLIP中的图像encoder换为任意的backbone,本文提出的finetune方法都适用
实验
分割实验
作者使用的baseline为SemanticFPN,并分别使用CLIP和DenseCLIP进行测试,结果如下:
主要结果:不管使用哪种backbone,DenseCLIP的性能都比那些使用了复杂decoder的分割方法性能好
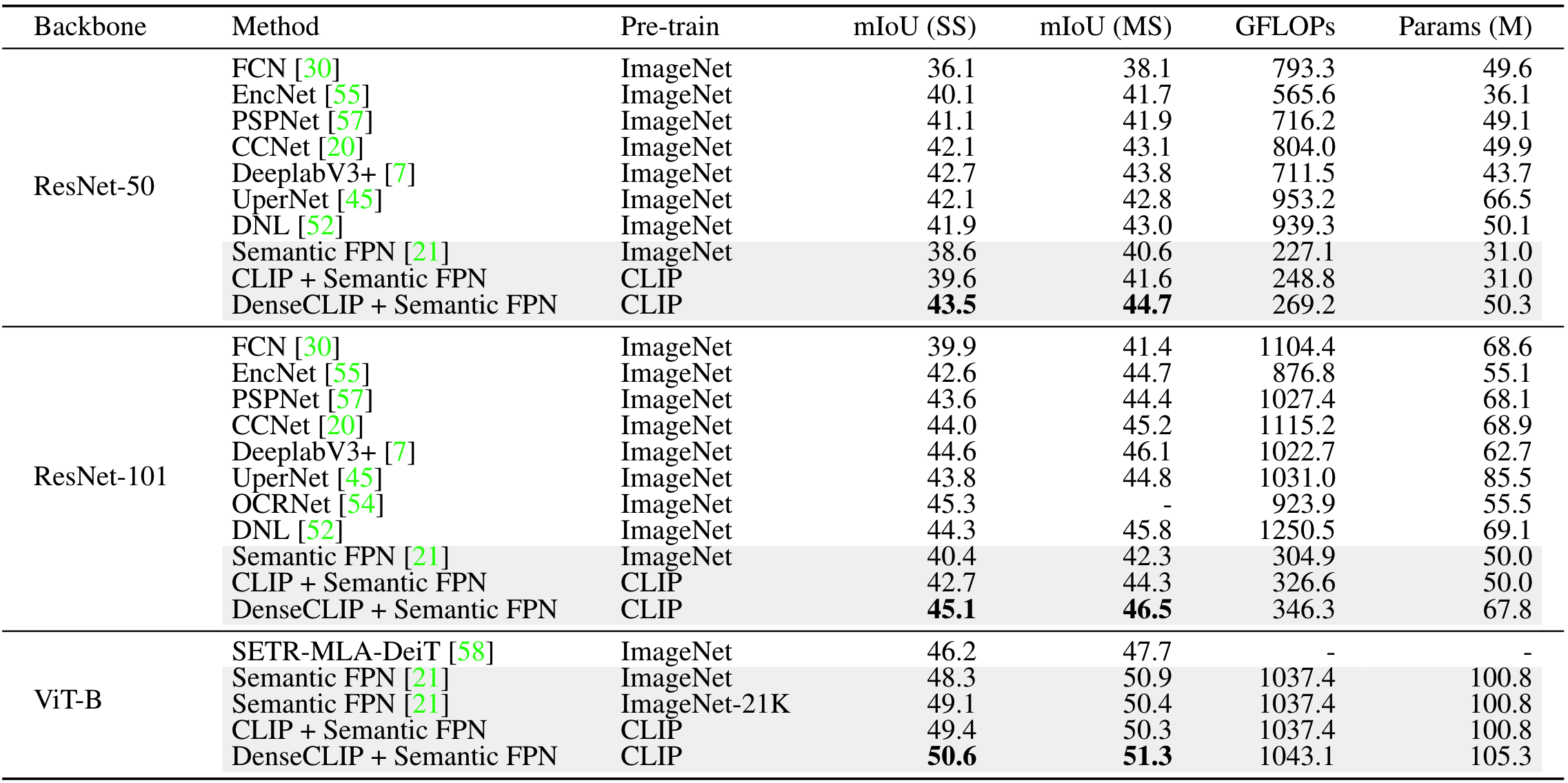
消融实验:消融实现表明,更好的训练策略、CLIP预训练、V-L prompting都可以提升模型性能

CLIP和DenseCLIP finetuning的效果:从对比中可以看到,使用CLIP直接finetune,效果要好于ImageNet 1K上的pretrain模型,使用DenseCLIP,效果要好于ImageNet 21K上的pretrain模型

检测和实例分割实验
在检测和实例分割任务上,使用DenseCLIP进行finetune的效果较其他方法都有所提升
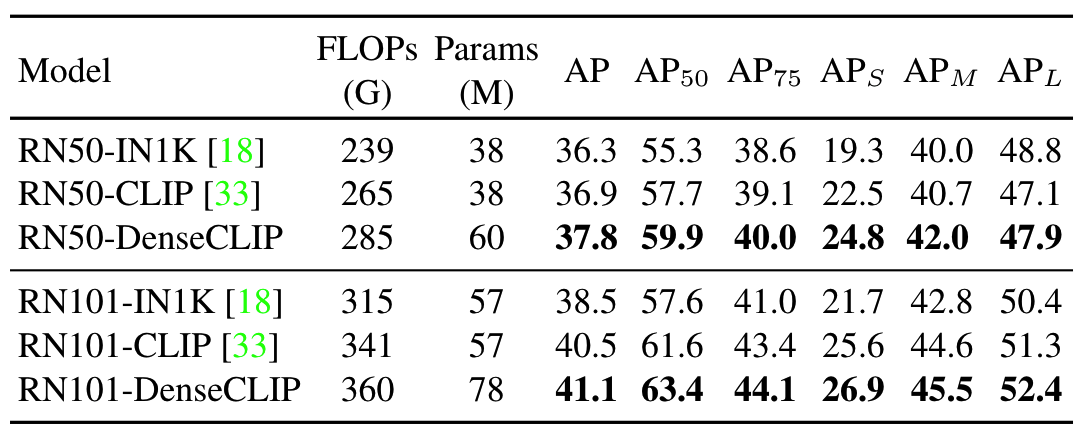
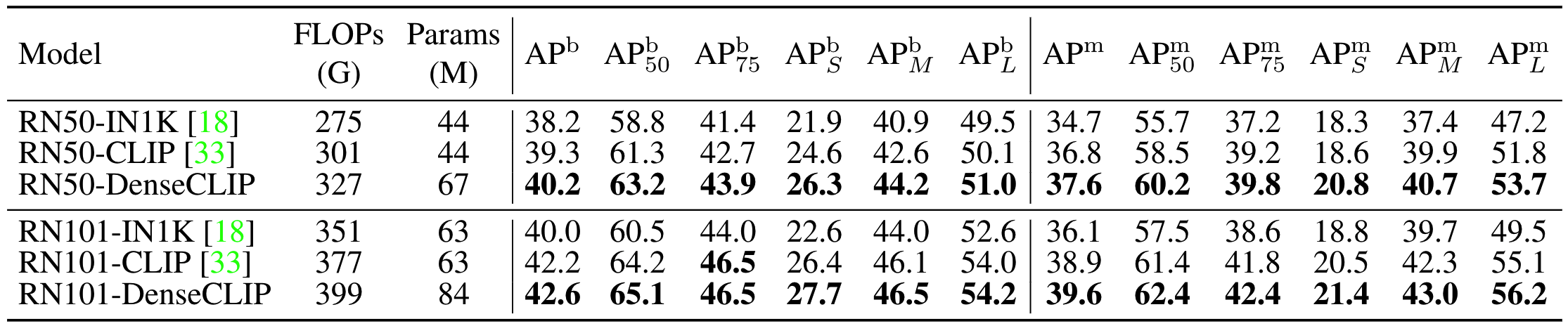
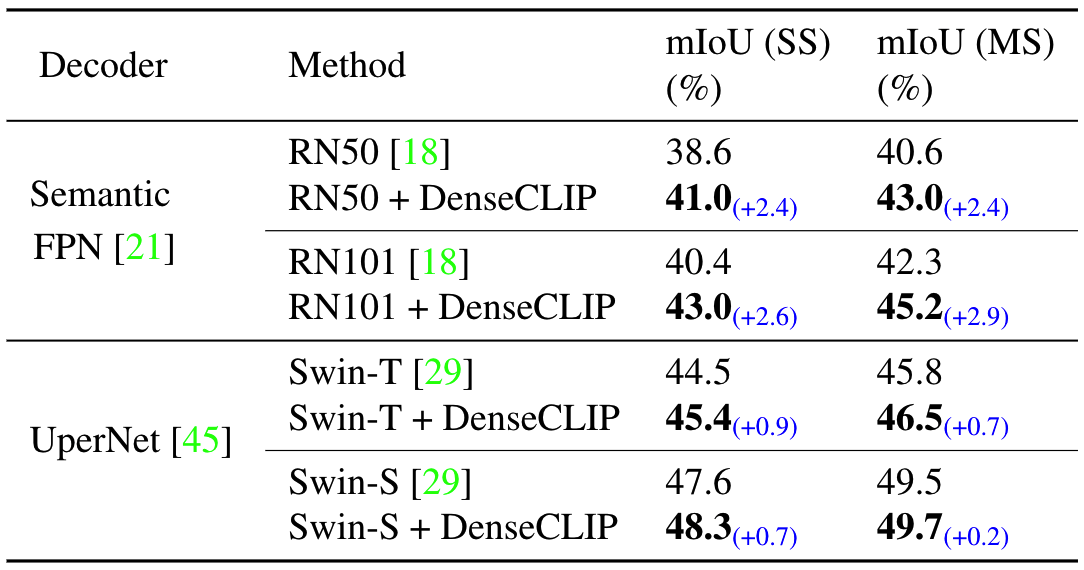
任意backbone
除了CLIP的image encoder,作者还使用其他预训练好的backbone作为image encoder进行finetune,实验结果表明性能都会有所提升
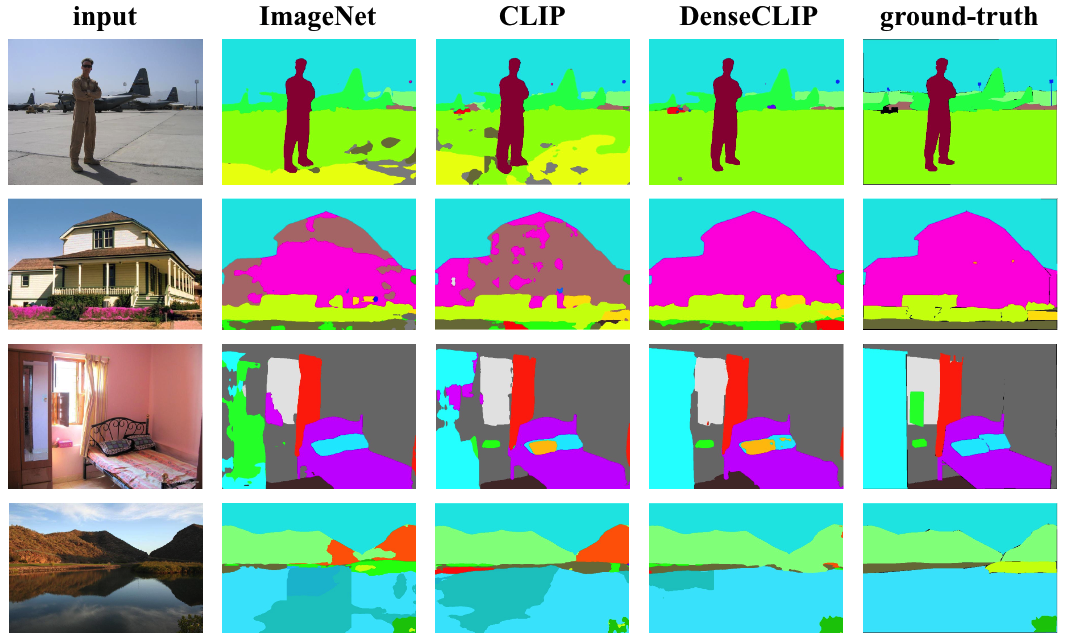
可视化
总结
本文提出了一种可以将CLIP模型迁移至需要密集预测的下游任务上的方法,可以用于语义分割、目标检测、实例分割等任务。但作者同时也提到在目标检测任务上提升没有那么大,可能是以目标为中心的任务缺少密集的监督所致。