论文笔记 - DeepSolo: Let Transformer Decoder with Explicit Points Solo for Text Spotting
前言
作者提出了一个简单的基于检测的transformer网络,该网络将序列建模成一个序列,并用一系列可学习的queries来表示,经过decoder的编码后,queries中已经包含了文本的语义信息和位置信息,可用于预测中心线、边界、文本以及置信度等一系列下游任务。同时本文还引入了一种基于文本匹配的loss,来更好的监督模型训练。实验表明,模型达到了SOTA且效率更好,在使用线条标注时,该方法也可以获得较好的结果。
论文:DeepSolo: Let Transformer Decoder with Explicit Points Solo for Text Spotting
代码:DeepSolo
背景
传统的text spotting方法一般采用的是先检测-后识别的框架,该方法有2个弊端:
- 检测和识别模块之间需要特征连接器(如ROI Pooling),且有些连接器要求文本框标注
- 需要解决2个模块之间的协同问题
基于segmentation的方法会将检测和识别作为2个独立的任务,进行并行优化,这种类型的方法需要复杂的后处理来将2个分支的结果进行组合
最近也有部分基于Transformer的方法,如TESTR、TTS等,这些方法也没有很好的解决检测/识别模型的协同问题:在TTS中,需要使用一个额外的RNN对特征进一步进行处理,以用于文本识别;TESTR则针对2个任务使用了不同的decoder。而且,这些方法中使用的query也有缺陷:TTS中使用的query和DETR类似,为通用的object query,并没有利用文本的特性如位置和形状;TESTR中,检测和识别模块使用的query并不相同。
本文提出了一种新的query形式,以及一种简单的transformer结构来同时完成检测及识别:
- 首先,作者使用贝塞尔曲线来拟合文本框,并在贝塞尔曲线上采样(固定点数),使用这些采样点生成positional queries,引导可学习的content queries
- 然后将encoder中提取的feature和queries输入decoder,得到output queries,获得对应的文本语义信息和位置信息
- 最后使用多个头来并行预测文本中心线、文本框、文本内容以及文本置信度
除此之外,作者还引入了一种文本匹配loss,来更好的利用文本标注信息进行监督,提高训练效率。
框架
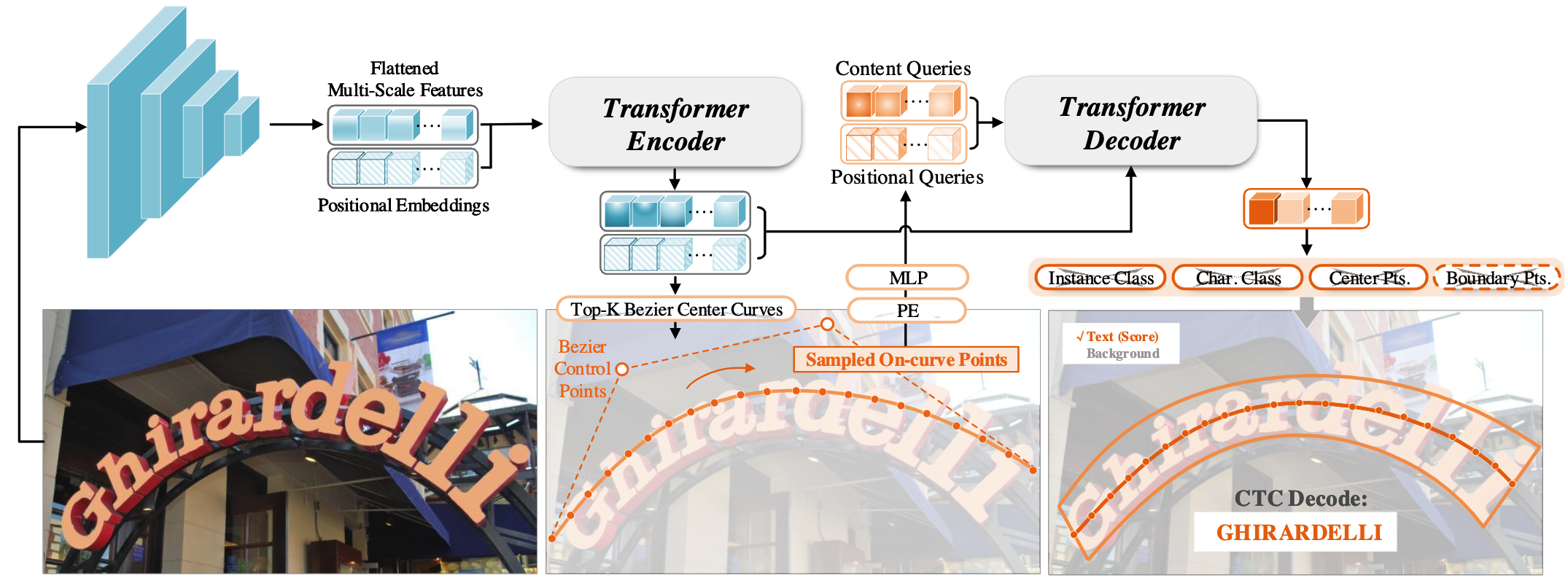
在该框架中,首先获得文本bbox的上下边缘的贝塞尔曲线控制点,然后对这两组控制点求平均后得到中线的控制点。然后再中线上均匀采集个采样点作为GT。
与TESTR类似,图像经过backbone获得特征后,首先经过transformer encoder预测中线控制点的proposal及score,选取top-k组控制点,计算得到曲线后进行均匀采样。这些采样点被编码成queries,输入transformer decoder,得到对应的feature,然后经过多个并行的head分别预测中线位置、文本边界等
Top-贝塞尔曲线控制点
输入为encoder不同level特征,经过一个3层的MLP,在feature map上的每个点,预测该点到一组(4个)贝塞尔曲线控制点的偏移量。同时,使用一个FC层来预测该位置属于文本区域的置信度,并据此选取Top-组贝塞尔曲线控制点的proposal
Point Query
初始化:获得组贝塞尔曲线控制点的proposal后,求出其曲线并在每条曲线上均匀采样个点,获得个坐标值,然后通过下列公式获得point positional query
为位置编码,MLP共有2层,将和一组可学习的point content query相加,得到最终的query
更新:首先求取组内的个采样点(同一个文本)的self-attention,即和相同,为point content query
然后再求组贝塞尔曲线控制点之间的self-attention,来学习不同文本间的关系。
更新过后的query输入decoder的后续层来进行cross attention,与Deformable-DETR类似,被用作参考点,然后在每一层,都会使用3层的MLP预测偏移量,并更新,并使用更新后的值计算新的point positional query
下游任务
经过decoder后,会得到一个 的向量,该向量会用于以下任务:
- 文本分类:使用一个全连接层预测该instance是否为文本,在推理时会使用个点的均值
- 文本识别:预测个字符(包含空格),用CTC的形式进行训练和推理
- 中心点:使用3层的MLP预测每个instance中心线的GT和参考点之间的offset
- 边界点:使用3层的MLP预测和上线边界点之间的距离
优化
使用匈牙利匹配算法将预测的个instance和GT来进行匹配,在计算cost时,TTS算法使用的CE loss,但由于预测的个字符和文本GT不等长,存在空格,因此字符不是一一匹配的,应该使用CTC。与Deformable-DETR一样,在计算分类cost的时候,使用的是focal loss,即,完整的cost计算公式如下:
最终的Loss为:
-
文本分类loss为focal loss:
-
文本识别loss为CTC loss:
-
中心点识别loss为L1 loss:
-
边界点识别loss为L1 loss:
Decoder部分总的loss为:
与TESTR类似,为了保证贝塞尔曲线控制点的proposal更加精确,在encoder部分也加入了对proposal的监督,为了使采样点更加接近GT,作者没有对控制点进行监督,而是对每个instance的个采样点进行监督, 即:
实验
消融实验
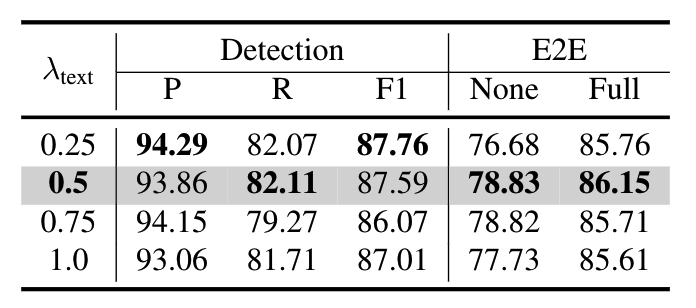
Text Loss权重:与TESTR类似,作者对比了不同的Text Loss权重的影响,在时效果最好
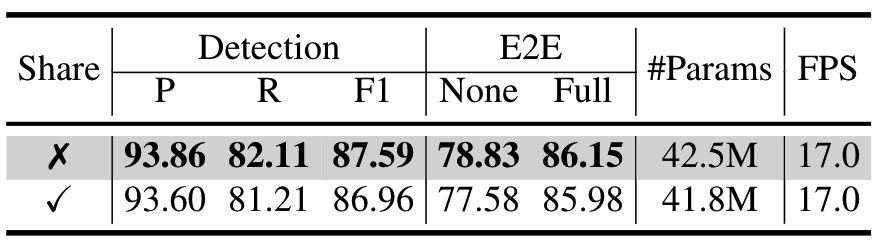
Point Embedding是否共享:在DeepSolo中,每个instance的point embedding都是分开计算的,作者对比了共享point embedding的性能,会有所下降
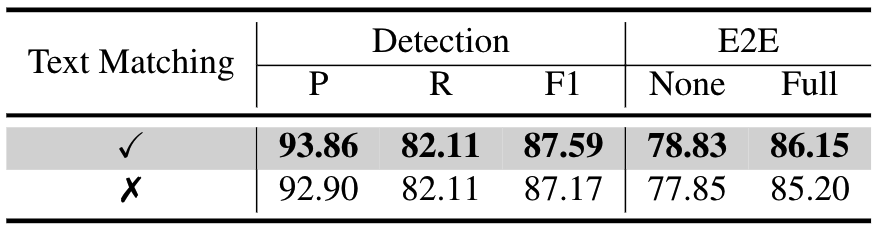
匈牙利匹配cost中文本匹配loss的影响:匈牙利匹配时不考虑文本匹配loss会导致性能下降
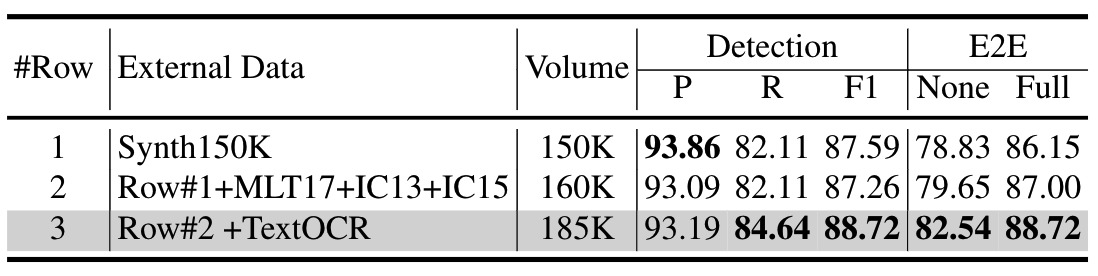
训练数据影响:对比在合成数据上的模型,加入真实数据模型性能有所提升,且数据量越多,性能越好,证明了数据的重要性及模型的扩展性
与现有的其他transformer方法对比,DeepSolo收敛更快,性能更好,且显存占用更低。与使用了2个decoder的TESTR对比,使用了一个decoder的DeepSolo性能反而更好

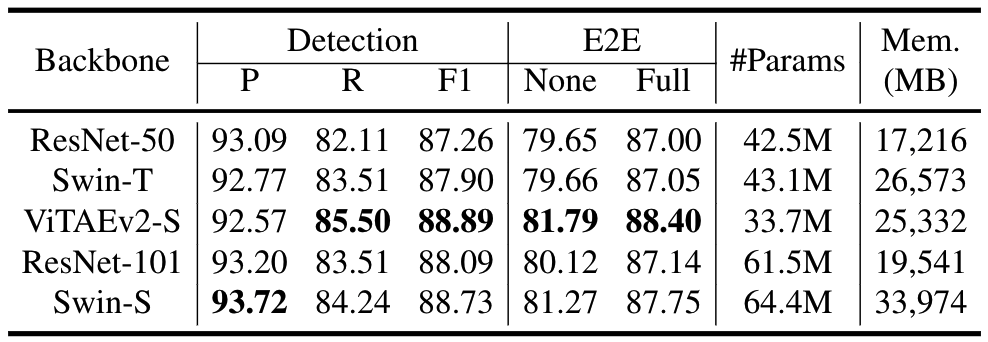
backbone影响:对比不同的backbone,ViTAEv2-S在大部分指标上最好,但在检测的precison上不如Swin-S,作者猜测为合成数据和真实数据上存在gap,导致不同的backbone性能存在差异,但具体原因仍需探究
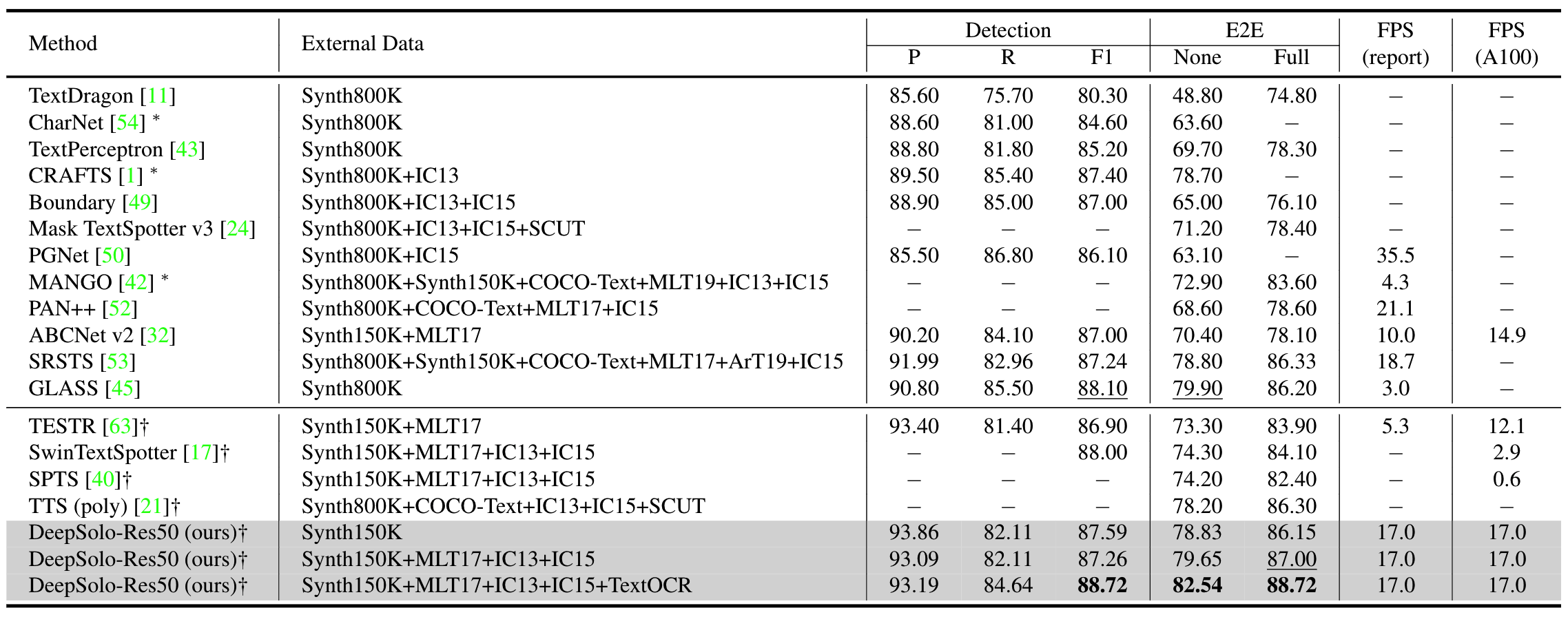
与SOTA对比
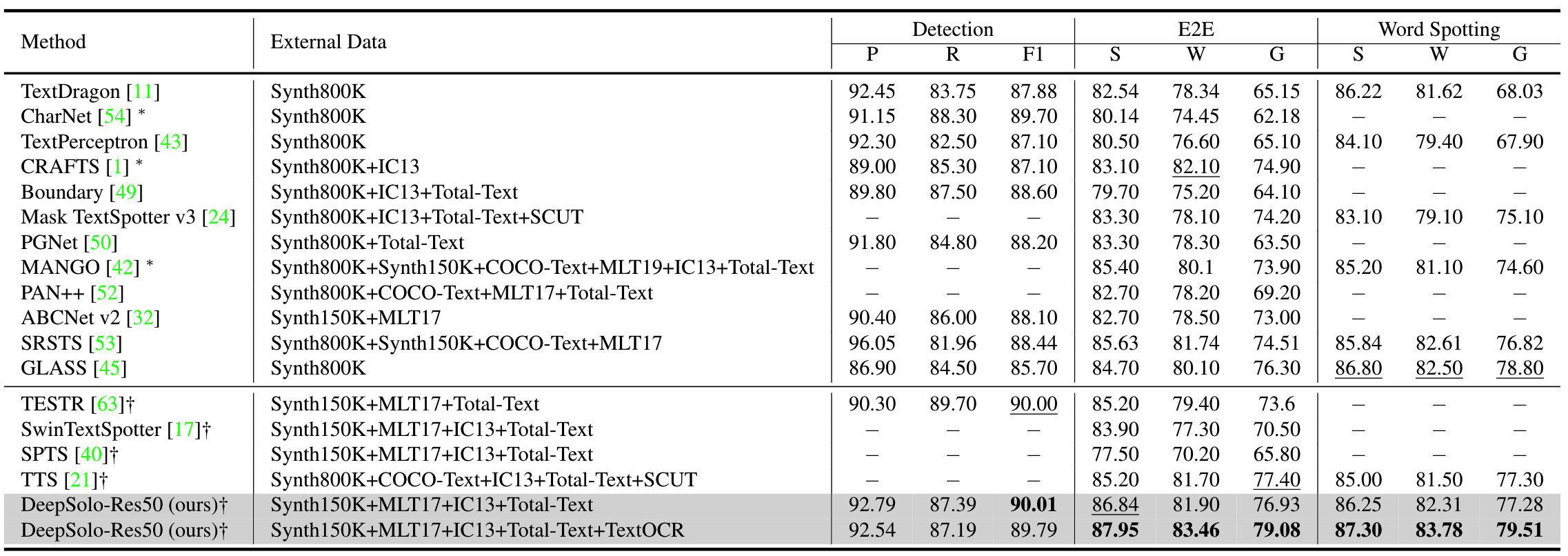
Total-Text数据集:在只使用合成数据时,在没有提供字典时,E2E的指标上,DeepSolo仅低于GLASS算法,且显著高于其他transformer算法;在加入常用真实数据后,DeepSolo的性能和GLASS相似,但速度更快;加上TextOCR数据后,DeepSolo成为SOTA
ICDAR-2015数据集:DeepSolo算法成为SOTA
可视化
可视化后的结果显示,DeepSolo能够识别不同尺度的文本,且能将注意力集中到字符上

使用弱标注的能力
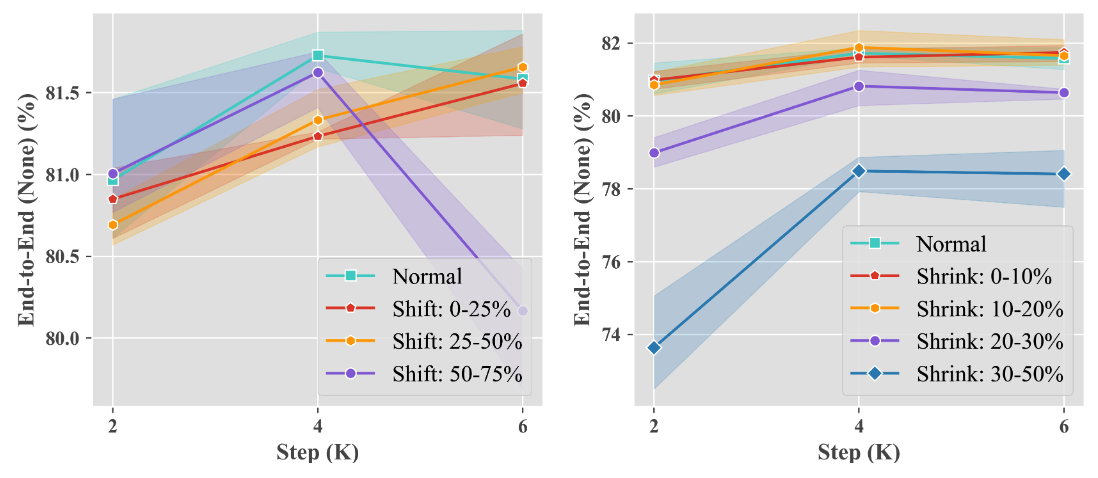
首先使用全量标注进行模型预训练,然后在total text上,去除文本框标注,以及对应的文本边界预测head,仅使用文本中线finetune模型,同时将文本中线进行随机向上方或者下方便宜,或者向中心收缩,来模拟标注错误,可以看出,性能下降不大