Scaling Language-Image Pre-training via Masking
前言
本篇文章为kaiming的新作,与MAE类似,将随机丢弃patch的方法用于clip,使得计算相同的文本-图片对时的显存占用显著降低,从而可以扩大每次计算的batch size, 在每个iteration计算更多图片-文本对的contrastive loss,在加速模型的同时,提升模型的性能。实验表明,在下游任务上,FLIP算法较CLIP由显著的提升。此外,本文还探讨了模型大小、数据集大小以及训练时长等方面的可扩展性
论文:[Scaling Language-Image Pre-training via Masking](2212.00794.pdf (arxiv.org))
背景
进来大火的CLIP算法,具有较强的zero-shot能力,且在图像文本生成方面有着前所未有的能力。它和我们常用的预先设定好的标签集不同,自然语言在多个粒度级别上提供了更加丰富的监督信息,如物体、场景、动作、背景和这些元素间的关系。由于自然语言和图像都很复杂,因此CLIP模型的训练需要大量的数据(400M)以及长时间(数千个GPU-days)的训练。这也制约了对CLIP的探索
为此作者采用了与MAE类似的思想,将图片中的patch进行随机丢弃,来实现:
- 在同样的训练时间里,模型可以见到更多的样本
- 在一个iter中使用同样的内存,模型可以对比更多的样本
样本丰富性的增加可以一定程度上缓解单个样本信息的丢失,带来模型性能的提升
通过随机丢弃50%-75%的样本,计算消耗降低了2-4倍,这使得模型可以使用2-4倍的batch size进行训练,如图所示,FLIP在达到同样准确率使用的时间缩短了3倍;训练同样的epoch,FLIP在速度提高2-3倍的同时性能更好
在下游任务上的实验表明,FLIP可提升模型的训练速度,同时提升模型的准确率
此外,作者还在3个方面探讨了FLIP的可扩展性,分别是:扩大模型尺寸、扩大数据集大小、增加训练时长,发现增大模型和数据集都可以提升模型性能,且扩充数据集可以在不增加训练成本的情况下提升性能
框架

图像掩模:图像encoder使用的是ViT,在随机丢弃50%或75%的图像patch后,ViT仅在剩余的patch上进行计算,因此计算消耗降为原先的1/2或者1/4,在显存相同的情况下,可以使用2x或者4x的batch size
文本掩模:作者尝试在文本上使用掩模,但由于文本encoder的计算开销较小,提升并不明显,因此文本掩模仅在消融实验时使用
优化函数:使用的loss与CLIP相同
为了降低掩模带来的影响,在刚开始训练的时候,mask ratio设为0%,可以取得更好的accuracy/time tradeoff
实现
模型的框架与CLIP/Open CLIP基本相同,除此之外,在text encoder部分,FLIP没有使用CLIP中的自回归Transformer,而是将文本序列pad至统一长度的序列,然后使用WordPiece转化为token
实验
消融实验
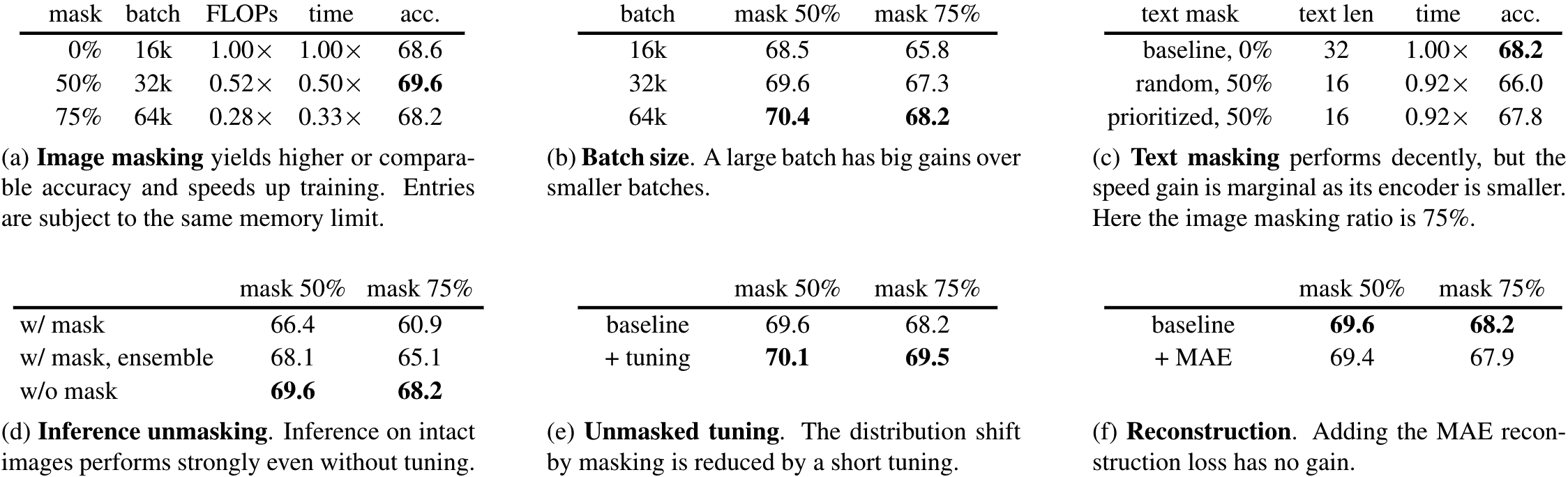
图像掩模比例:对比不同的掩模比例,batch size也相应的做了提升,发现使用50%的比例提升了1.2%的性能,75%的比例时,与CLIP差不多,但计算时间都有所降低
Batch Size:从实验(b)看出,增大batch size可以增加模型性能,同样是使用16k batch size,(b)中使用50%掩模比例的性能与(a)中无掩模的性能相当,证明掩模引入的正则化监督可以抵消过拟合
文本掩模比例:由于文本中的信息含量较高,因此掩模的比例应该较低。因为FLIP将文本pad至同样长度的序列,因此可以通过此先验知识来较多的将pad token进行掩模,实验发现,文本掩模会使性能降低。因为text encoder占用的计算资源不多,因此对文本掩模并没有收获较多的trade-off,所以在其他实验中并没有对文本进行掩模
推理时不进行掩模:尽管掩模是训练和推理2个模态间的gap,但是在推理阶段不进行掩模的效果却还不错。而进行掩模后,由于信息的损失,推理的性能下降较大,即使通过ensemble来减缓信息的损失,性能也不如整张图片进行推理
不掩模的调优:在刚开始训练(最初的0.32 epoch)时,使用不掩模的图片进行tuning,会提升1.3%的准确率。
图像重建:加入像MAE类似的图像重建loss,会对性能有为微小的负面影响,因此在后续实验中不使用图像重建loss
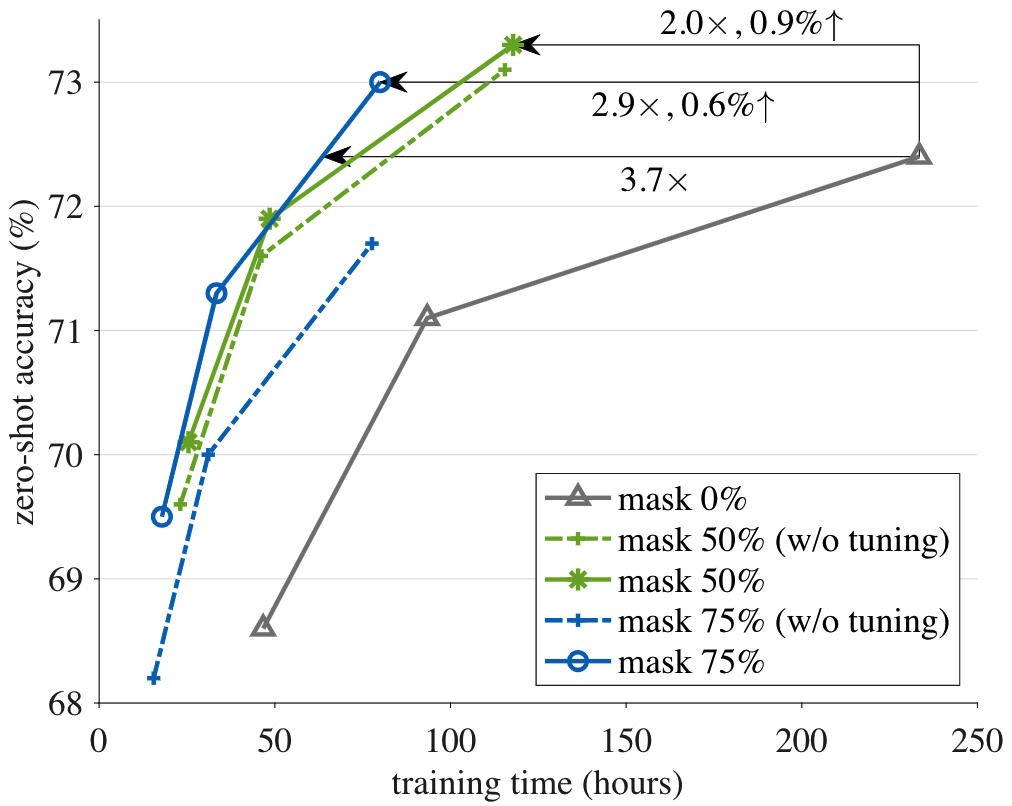
准确率 vs 时间 trade-off:拉长算法的训练时间(6.4->12.8->32),可以看出FLIP的trade-off要优于CLIP,在32 epoch的实验中,使用50%的mask比例,FLIP在比CLIP快2倍的同时,性能提升了1%
与CLIP对比
在后续的实验中,作者对比了3种CLIP:
- 原版CLIP的checkpoint,使用私有的WIT-400M数据集徐娜林
- OpenCLIP,在LAION-400M数据集上训练
- 复现的CLIP,在LAION-400M数据集上训练
如果与原版CLIP直接比较,除了方法的影响,还有数据集带来的影响;对比OpenCLIP可以消除数据的影响;对比复习的CLIP可以排除其他的影响,更加精确的对比FLIP的效果

ImageNet zero-shot transfer:直接使用预训练的权重在ImageNet上测试性能,原版CLIP>复现CLIP>OpenCLIP,原版CLIP最高可以认为是数据集的影响。而FLIP要高于复现CLIP和OpenCLIP,且与原版CLIP的差距进一步缩小至0.7%

ImageNet linear probing:固定backbone,训练一个fc用于分类,FLIP优于复现CLIP、OpenCLIP、转化权重后的原版CLIP
ImageNet fine-tuning:在此设定下,原版CLIP仍然是最优,同时FLIP优于其他CLIP

其他数据集上的Zero-shot classification:在此实验上可以观察到与训练数据带来的影响,原版CLIP在某些数据集上性能较好,再其他数据集上则不如FLIP

Zero-shot retrieval:FLIP优于所有的CLIP,证明在这样的任务中,WIT数据集对LAION数据集没有优势

Zero-shot robustness evaluation:在这个实验上又一次观察到训练数据集的影响,在某些数据集上,FLIP已经大幅超过了除原本CLIP的其他版本CLIP,但性能依然远不及原版CLIP。抛开数据集的影响,FLIP算法优于其他CLIP

Image Captioning:在这个实验的某些指标中,FLIP已经优于原版CLIP,且明显优于其他版本CLIP
VQA:原版CLIP最佳,FLIP优于其他版本CLIP
总结:在相同的预训练数据集上,FLIP要优于CLIP的性能。与原版CLIP性能的差距是由于WIT和LAION数据集的不同引起的
扩展性
作者分别对比了3个维度的扩展性:1)更大的模型 2)更多的数据(32 epoch x 400M / 6.4 epoch x 2B) 3)更长的训练时间(32->64 epoch)
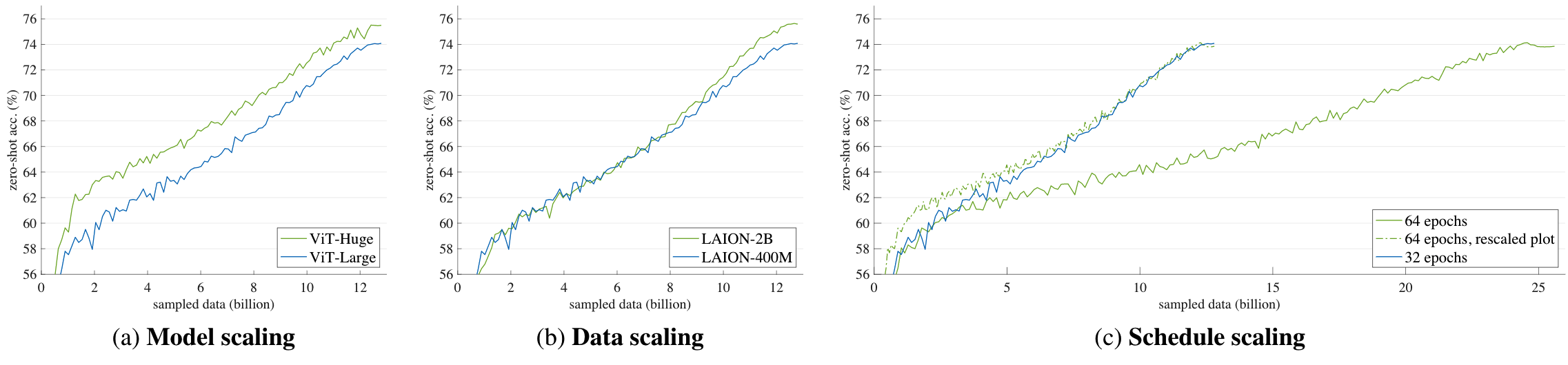
从训练过程中的曲线来看:
- 模型的增大在整个训练过程都有提升
- 数据的增多在训练初期效果不明显,但在后期有提升(使模型可以见到更多的数据)
- 更长的训练时间几乎没有收益(模型见到的数据多样性不变)
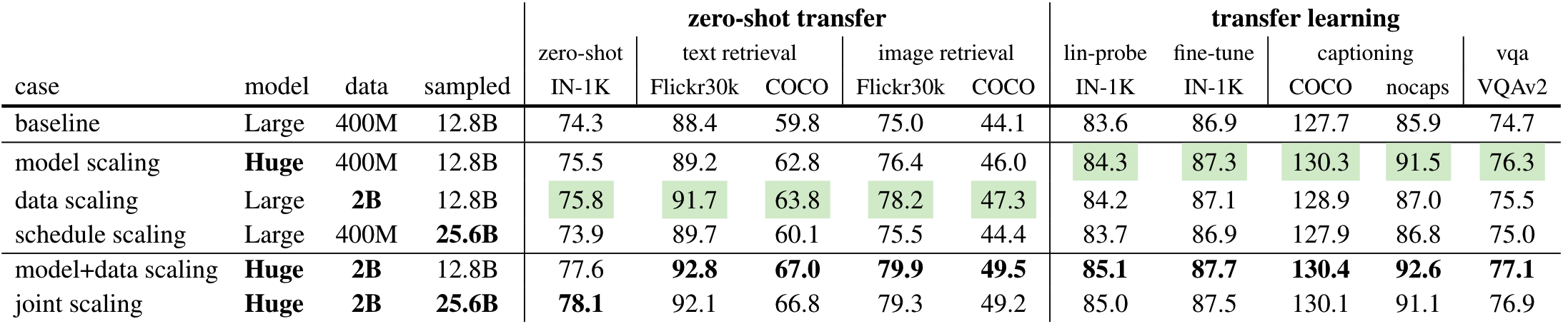
作者将下游任务分为2种不同的类别:1)zero-shot transfer:无需在数据集上继续训练。2)transfer learning:部分模型需要finetune。发现增大数据集对zero-shot transfer更有用,增大模型对transfer learning更有用
同时增大模型和数据集,取得性能提升大于单独增大其中一个,这说明,更大的模型需要更多的数据来充分挖掘其潜力
将所有的3个扩展性进行混合,仅有部分任务有提升,其他任务中的指标都有下降。