A Survey of Large Language Models
Intro
NLP模型分类:
- Statistical language models (SLM):基于统计,把word prediction建模为马尔科夫过程,使用最近的$n$个单词进行预测
- Neural language models (NLM):使用神经网络,输入为文本,输出word分布的概率,使用如RNN,word2vec
- Pre-trained language models (PLM):在无标注文本上pretrain一个基础模型,在有标注的数据集上进行finetune,即遵循”pretrain-finetune”范式。代表性工作如BERT
- Large language models (LLM):PLM的尺寸扩大版本,随着尺寸扩大,会带来”涌现”能力。代表性工作如chatGPT
LLM和PLM的三点不同:
- LLM具有涌现能力
- 改革了人类和大语言模型交互的方式,人类需要将任务转化为LLM可以理解的形式(prompt),来利用大模型的能力
- 模糊了算法和工程的边界,因为训练大模型需要较多的工程优化(并行、降低显存、数据收集清洗等)
LLM带来的挑战:
- 涌现能力的来源未知
- 学术圈无法从零训练LLM(资源、数据的限制)
- LLM的产出和人类的喜好或评判价值还没有很好的align(产生不良的文本等)
论文关注的四个点:
- 预训练
- fintuning
- 应用
- 评价(evaluation)
Overview
大模型的涌现能力:
在小模型里没有表现出来,但是随着模型尺寸增大,在模型中出现的在复杂任务上性能大幅提升的现象,代表性能力如下所示:
- In-Context Learning: 主要是指GPT-3的能力,通过提供任务描述或者NLP的指示,大模型不需要额外的训练或者finetune,就可以产生期望的结果
- Instruction Fllowing: 通过提供多种NLP形式的数据集进行finetuning,LLM即可在未见过的任务上表现良好,表现出良好的泛化性
- Step-by-Step Reasoning: 小模型一般无法多步求解。借助chain-of-thought reasoning策略,大模型可以通过包含中间步骤的prompting机制,得到最终结果
大模型的关键技巧:
- Scaling: 涌现能力出现的最关键的技巧,GPT-3(175B),Palm(540B),此外,数据质量也很重要,因此需要好的数据收集和清洗策略
- Training: 需要使用多种并行策略进行分布式训练,可以使用现有的多种框架,如DeepSpeed和Megatron-LM,此外优化策略也很重要,如重启(防止loss spike)和混合精度训练
- Ability elicting: 需要设计合适的任务描述来激发模型的能力,例如通过chain-of-thought完成多步求解,或者通过instruction tuning来提高LLM在未见过的任务上的泛化能力
- Alignment tuning: LLM是在质量参差不齐的预训练数据上训练的,因此可能会产生有害数据,因此需要让LLM的输入和人类的评判价值进行alignment。例如Instruct GPT使用了RLHF来对LLM进行tuning
- Tools manipulation: LLM是在预训练的文本上训练的,因此LLM的能力一般限制在预训练数据集中且在非文本任务上表现不好,因此可以通过外部工具来弥补LLM的不足,从而扩展ChatGPT的能力
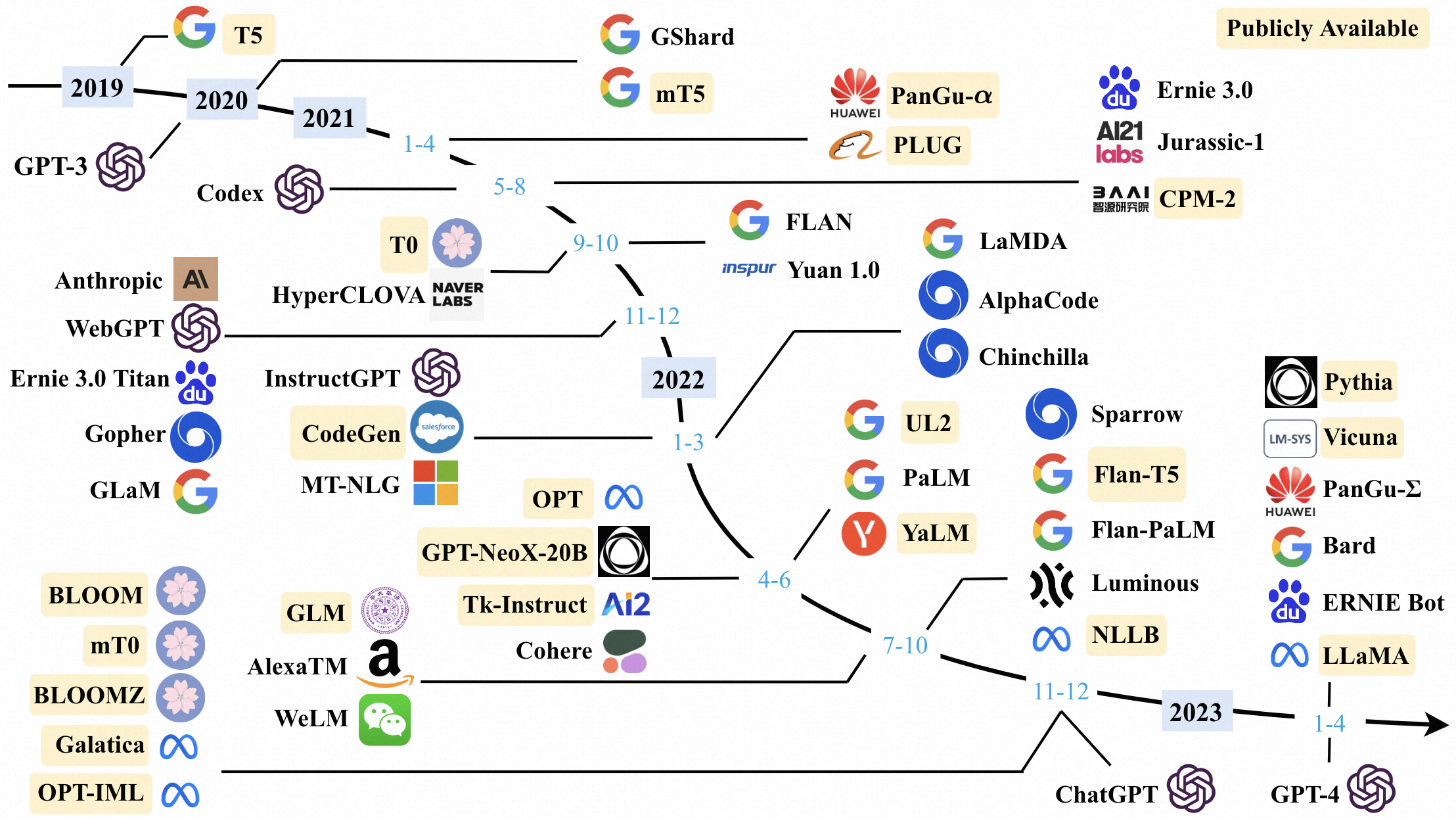
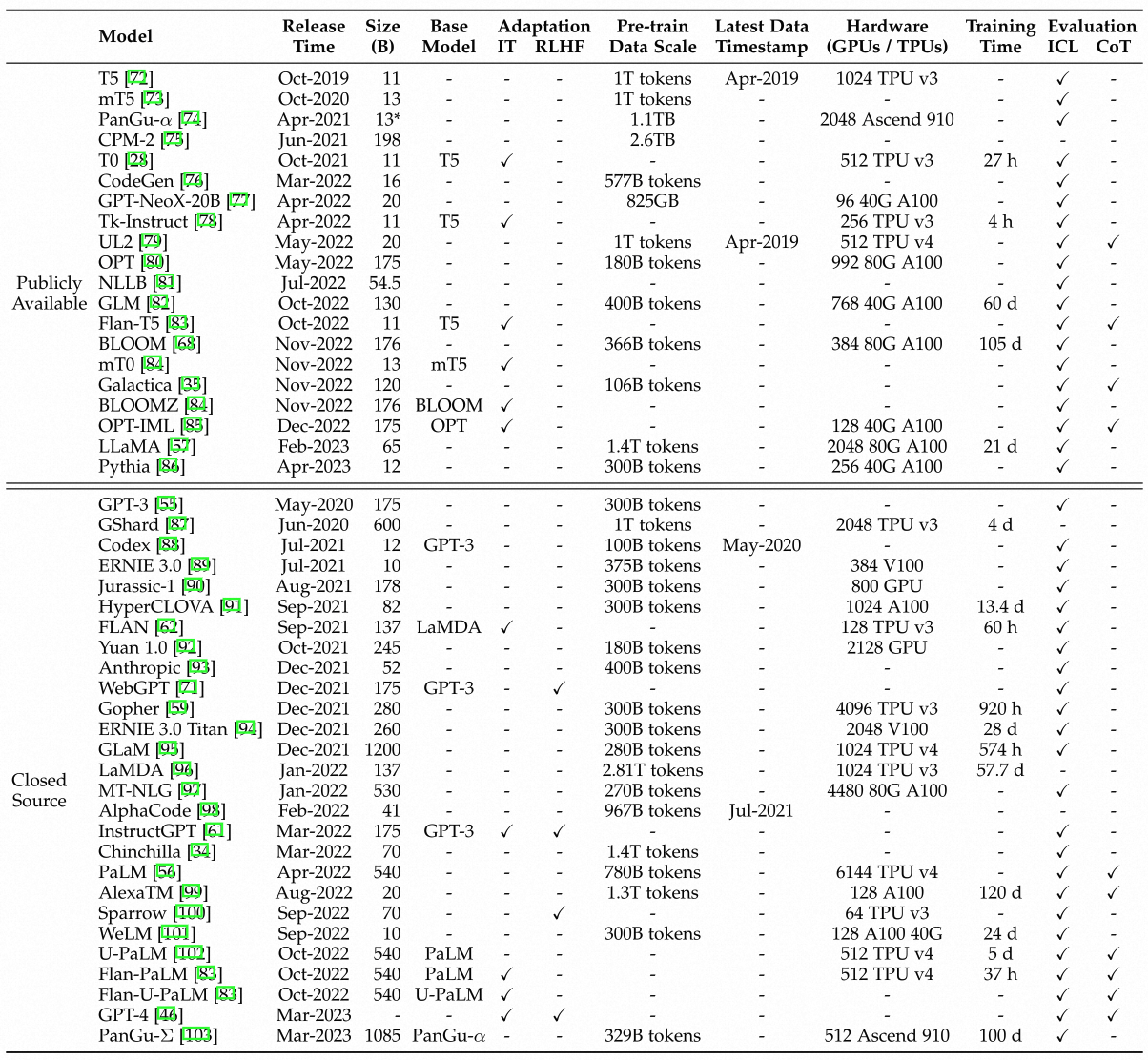
大模型资源
开源模型
- 十B级别:参数量10B-20B,如LLaMa-65B,Flan-T5,PanGu-a
- 百B级别:BLOOM-176B,BLOOMZ-176B
- API:GPT-3(davinci),GPT-3.5(code-davinci-002,text-davinci-002,text-davinci-003,gpt-3.5-turbo-0301),GPT-4
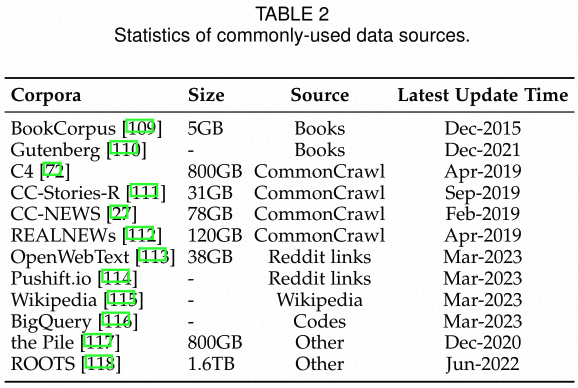
开源数据
- Books:BookCorpus, Project Gutenberg
- CommonCrawl:CommonCrawl,C4,CC-Stories,CC-News,RealNews
- Reddit Links:OpenWebTex,PushShift.io
- Wikipedia:
- Code:BigQuery
- Other:Pile
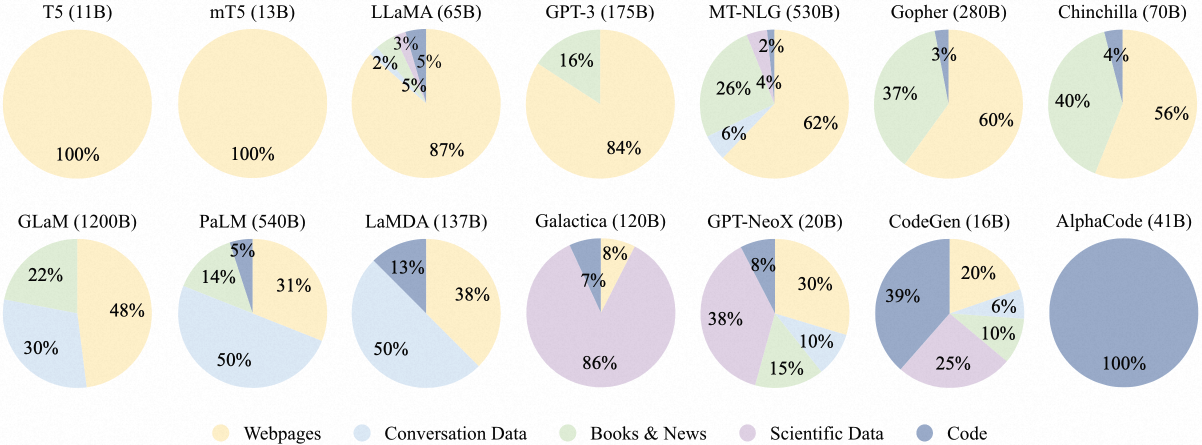
LLM的pretrain需要多种混合数据源作为训练数据,如以下三种代表性LLM需要的数据:
- GPT3-175B:混合数据集,包括300B token,包括CommonCrawl, WebText2, Books1, Books2 , Wikipedia
- Palm-540B:混合数据集,包括750B token,包括social media conversations,filtered webpages, books, Github, multilingual Wikipedia, news
- LLaMA:CommonCrawl, C4, Github, Wikipedia,books, ArXiv, StackExchange。其中6B,13B版本使用了1.0T token,32B和65B版本使用1.4T token
代码框架
- Transformer(Hugging Face),
- DeepSpeed(MicroSoft):训练大模型,包括各种并行策略,内存优化等
- Megatron-LM(Nvidia):训练大模型,包括各种并行策略,混合精度等
- Jax(Google):不同硬件上的计算加速
- Colossal-AI(HPC-AI Tech):训练大模型,包括各种并行策略,异构内存优化
- 其他
预训练
数据收集
大模型对于高质量数据的需求很高,因此需要关心数据收集及数据处理
数据源
数据源主要分为两类:
- 通用数据用于提升模型的建模和生成能力:
- 网页:主要通过爬虫,质量参差不齐,需要进行数据预处理
- 书籍:提升模型的语言知识,建模长时间的依赖性,产生连贯并且叙事性的文本
- 对话:提升对话补全和QA能力,从社交媒体上收集,由于可能存在多个参与者,因此会整理成树形结构,但潜在风险是:陈述性指示和直接疑问句被错误地理解为对话的开始,从而导致指示的有效性下降
- 专业数据:
- 多语言数据:提升大模型的多语言理解和生成能力,如Bloom和Palm
- 科技文本:提升大模型的对科学知识的理解和推理,如arxiv等,但像公式、蛋白质序列等需要经过特殊处理以形成token
- 代码:大模型在大量代码文本上进行pretrain可以提升代码生成能力,达到专家级别。语料来源于代码问答社区(StackExchange)和代码社区(Github)。有研究表明,在代码上的训练时大模型复杂推理能力的来源
数据预处理
通过数据预处理去除语料中的低质量文本
- 通过过滤来移除低质量文本
- 使用分类器:需要训练,但可能会移除部分高质量文本,有可能会带来训练集上的偏置
- heuristic:主要方法有几种:1) 基于语种过滤 2) 基于文本的质量指标进行过滤 3) 基于统计指标进行过滤 4)基于关键词进行过滤
- 去重:重复文本会降低多样性
- 句子级别:包含重复词语的句子要删除
- 文件级别:根据特征的重合程度删除重复的文件
- 数据级级别:训练集-测试集之间需要去重
- 去除隐私:爬取的文本中包含个人因此,需要通过规则去除。因为个人隐私存在重复,因此去重能在一定程度上缓解
- Tokenization:将文本转化为tokens,直接使用已有的tokenizer不如使用专门设计的

预训练数据对LLM的影响
LLM比较难训练,因此需要构建一个质量较高的数据集
- 混合训练集:不同来源的数据集有不同的语言特性,因此在混合数据集上训练能极大提升大模型的能力。但是在混合时,需要根据不同的需求来确定不同数据集的分布比例。
- 训练数据量:训练LLM需要使用和参数量匹配的数据量。LLaMA表明使用更多的数据和更长的训练时间可以让小模型也有更好的表现。因此,扩大模型时,需要注意高质量训练数据的量,使模型可以充分训练
- 预训练数据的质量:低质数据会降低模型的性能,因此需要对预训练数据集进行预处理
模型结构
主流结构
Transformer:可并行性和可扩展性非常好,因此LLM都用这种结构
- Encoder-Decoder架构: encoder使用multi-head self-attention,将输入序列编码为隐变量。decoder使用cross-attention,通过自回归方式产生目标序列
- Causal Decoder Architecture(Decoder-Only): 使用单向的attention mask,确保token只能看到之前的token和自己,input和output都是如此处理。GPT系列模型,Bloom使用的是该种架构
- Prefix Decoder Architecture:在prefix token部分(如输入的prompt)使用双向mask,token之间能够互相看到。在generated token(如输出的答案)上使用单向mask,保证只能看到之前的token和自己
以上三种架构可以通过多专家机制进行混合使用
具体配置
- Normalization: Transform一般使用LayerNorm,且为post-LN。在LLM中,起初使用pre-LN(训练稳定但性能会下降),后来会有多种变体,如RMS Norm,DeepNorm
- 激活函数:LLM一般使用GeLU,以及其变体,SwiGLU或者GeGLU(参数量会增加)
- 位置编码:transfomer一般使用sinusoids和learned position embeddings两种位置编码,LLM中一般使用后者或者其改良版ROPE(乘以特定的旋转矩阵)
- 注意力机制和偏置:Transformer一般使用全量的self-attention,LLM考虑到GPU显存和计算效率的问题,如GPT使用的是sparse attention。大部分的LLM都保留了bias,但是PaLM中说没有偏置有利于训练稳定性
综上,LLM一般使用pre RMS Norm,SwiGLU或GeGLU,ROPE或者AliBi
预训练
预训练最重要,将大规模语料中的通用信息编码至大模型中,主要方式包括Language Modeling和 Denoising Autoencoding
- Language Modeling:常见的Decoder-Only模型常用,如GPT系列,Palm等。根据前i个token预测第1+1个token(自回归),最小化预测的loss,即:
$$L_{LM}(x)=\sum_{i=1}^{n}log P(x_i | x_{<i})$$
LM的一个重要变种是prefix language modeling,为带有prefix decoder结构的模型预训练设计,随机选择的前缀得到的token并不会用于计算loss,性能会弱于LLM
- Denoising Autoencoding:将文本随机的掩盖部分字符,让LLM进行填空,比LM更加复杂,Loss为:
$$\mathcal{L}{D A E}(\mathbf{x})=\log P\left(\tilde{\mathbf{x}} \mid \mathbf{x}{\backslash \tilde{\mathbf{x}}}\right)$$
总结:
- 使用LM Loss进行pretrain,使用casual decoder能够获得更好的性能以及few-shot/zero-shot能力,通过instruction tuning和alignment tuning,模型能力可以进一步增强
- Scaling Law:对模型尺寸,数据集尺寸和计算,casual decoder能力提升很快
模型训练
Optimization Setting
- Batch training:动态增长batch size有利于训练的稳定性,如GPT动态的将batch size由32K增长到3.2M tokens
- Learning Rate:
- 初始的0.1%-0.5% step:Linear warm-up,将lr逐步提升至最大值, 如从$5 \times 10 ^ {-5}$提升至$1 \times 10 ^ {-4}$
- 后续step:cosine decay strategy,将lr由逐步下降至最大值的10%,知道trainging loss收敛
- Optimizer:Adam或AdamW,参数设定通常为:$\beta_{1}=0.9, \beta_{2}=0.95, \epsilon=10^{-8}$ 。T5和PaLM为了保留GPU内存中的内容,使用了Adafactor优化器
- 训练稳定性:
- 使用gradient clip(设置为1.0)和weight decay(设置为0.1)
- PaLM中使用了跳过策略:在模型崩溃前,reload初始的checkpoint并跳过容易导致崩溃的数据
- GLM中缩小了embedding层防止崩溃
Scalable Training Techniques
LLM模型尺寸较大,但计算资源有限,需要解决两个问题:增加训练的吞吐以及在GPU中load更大的模型,主要用的技巧包括:
- 3D并行:3种常用的并行策略
- 数据并行:将数据分割到N块卡上,每块卡持有完整的模型,只使用分配的数据训练,求梯度时进行汇聚,得到整个batch的梯度。→通过增加卡数即可提高模型的吞吐量,且实现简单
- Pipeline并行:将LLM的不同层分布到不同的GPU上,对于transfomer会将相邻的层分配到同一块GPU以减少计算attention的数据交换。→降低计算效率,后面的层要等前面的层计算完成。→ Gpipe和PipeDream通过padding和异步封信减少额外的开销
- Tensor并行:将LLM的权重tensor分解到多个GPU上进行计算,然后通过GPU间通信进行合并。现有的很多框架已经支持,如Megatron-LM,Colossal-AI
- ZeRO:DeepSpeed框架,解决数据并行中的内存冗余。数据并行中,每个GPU需要保存整个模型的数据(参数、梯度、优化器),造成数据冗余。 → 每个GPU仅保存一份,其他数据在需要时从其他GPU上获取 → 提供了三种解决方式:optimizer state partitioning, gradient partitioning, parameter partitioning。前两个基本不增加计算开销,第三种会增加50%的通信开销,但是会减少1/N的内存开销(N为GPU数量)
- 混合精度训练:PLM常用FP32,LLM使用FP16能够减少内存/显存开销,且GPU卡FP16运算能力更强,但是FP16会损失训练精度。使用BF16(Brain Floating Point)可以减少精度损失,其分配给指数的位数更多,分给整数的位数更少
总结:以上的训练优化策略经常被混合使用,且现有的框架(DeepSpeed, Colossal-AI等)对上述策略有很好的支持;提高模型inference的速度也很重要,常用的手段包括int8量化,甚至int4量化
Adaption Tuning of LLM
Pretrain仅让模型学习到了通用的能力,需要进一步的tuning来提高LLM在不同任务上的性能,主要包括两种:instruction tuning(加强模型能力)和alignment tuning(使模型更符合人类的评判标准)
Instruction Tuning
在以NLP格式整理好的instances上进行tuning,与监督学习相关。
- 收集instruction-formatted instances
- 以监督方式进行finetune(例如使用seq-to-seq loss)
Formatted Instance Construction
Instance: 任务描述(instruct) + 输入-输出对 + 少量的示范(可选),开源资源如下:
常用的构建方式如下:
- 格式化现有的数据集:给现有的数据集增加描述,说明任务的目的,帮助LLM理解。有研究表明instruction是LLM泛化能力的关键。或者根据已有的instance,让LLM生成新的instance
- 根据人类需要构建:前者缺乏多样性,且跟真实人类的回答存在差距。InstructGPT通过API收集用户提交的querie作为任务描述,此外还让一部分标注者根据显示现实生活编写instruction,另一部分标注者给出输出,形成完整的instance。
- 构建instance的关键因素:
- instance数量:一开始随着instance数量增加,模型能力增加,后面便会饱和,部分task上,过多的问题反而会导致过拟合。但是在长度、结构等方面丰富instance的多样性是有益的。
- 格式设计:任务描述最关键,提供部分样例能够减少模型对instruction的敏感性。CoT可以引发出模型的step-by-step的resoning能力
总结:
- instruction的多样性比instance的数量更重要
- 人工标注的instance比数据集生成的instance更有效
Instruction tuning strategies
tunning和training有较多不同,如训练使用的数据量小,使用seq2seq的监督loss,batch size和lr更小等,需要格外注意的有以下两点
- 平衡不同数据集的分布:tuning过程使用功能的数据是多个task的混合数据,因此需要注意分布的平衡,可以采用等量、高质量数据更多的分布、或者最大数量首先的分布
- 合并预训练和tuning:在tuning中使用pretrain的数据,可以使训练更稳定;或将tuning数据作为pretrain数据中的一小部分
tuning的做作用
- 性能提升:tuning可以提升或解锁LLM的能力,这点在所有尺寸上的LLM上都有所体现,通过tuning,小模型甚至可以超过大模型(未tuning)的表现。需要的资源耗费比pretrain要小,是提升模型能力的好方法
- 任务的泛化性:通过tuning,可以激发出LLM的能力(涌现),遵循人类的描述,可以在没有见过的任务上表现良好;在英语上tuning过的模型,在其他语种的任务上能力也有提升,可以减少针对不同语种构建Instruction的工作量
Alignment Tuning
背景和评价方式
- 背景:LLM的训练方式(word prediction)导致其产生的答案和人类喜好有偏差,因此需要alignment tuning,但是会降低性能(alignment 税)
- 评价方式:
- 有用(helpfulness):LLM模型给出的输出应该简洁且有用,帮助用户完成任务。-> 较难,因为用户的意图难以度量
- 诚实(honesty):LLM模型给出的答案应该准确而非编造,因此模型需要知道自己不知道什么 -> 比较好衡量
- 无害(harmless):LLM模型给出的答案应该没有冒犯性和歧视性,需要拒绝回答不好的prompt
三种评价范式都是根据人类的认知确定,非常主观,很难衡量。可以通过红蓝对抗方式进行评测
收集人类反馈
高质量的人工标注对于LLM和人类喜好的alignment很重要
- 人类标注员的选择:需要一定的受教育程度和专业性,如果与研究者的期望相差太大会导致意外输出的出现->研究者标注一个小数据集用于衡量和标注员之间的匹配度,选择最高的作为标注员,并将最好的部分标注员作为超级投票者
- 人类反馈收集:
- 基于排序的方法:标注着给模型输出排序。早期研究只选最模型产生的最好答案。但是不同标注者对哪个答案最好可能意见不同。因此需要采用Elo Ranking方法,用基于排序的方法,让模型更倾向于某个答案
- 基于QA的方式:标注者回答研究人员提出的问题。
- 基于规则的方式:标注者除了选择最好的回答,还需要评判回答是否违反了一系列规则(有用、诚实、无害等)。从而得到2种反馈:
- 更倾向于哪个回答(两两比较)
- 回答违反规则的程度
RLHF
算法由3部分组成:
- 需要被align的预训练语言模型,如GPT3用的是175B模型
- 用于给LM输出进行打分的reward model,可以选择finetune后的语言模型/用人类喜好数据重新训练过的LM,一般参数规模与pretrained-LM不同,GPT-3用是6B模型
- 训练语言模型的RL算法,根据reward model出的reward来优化pretrained LM,一般使用PPO算法
具体工作流程如下所示:
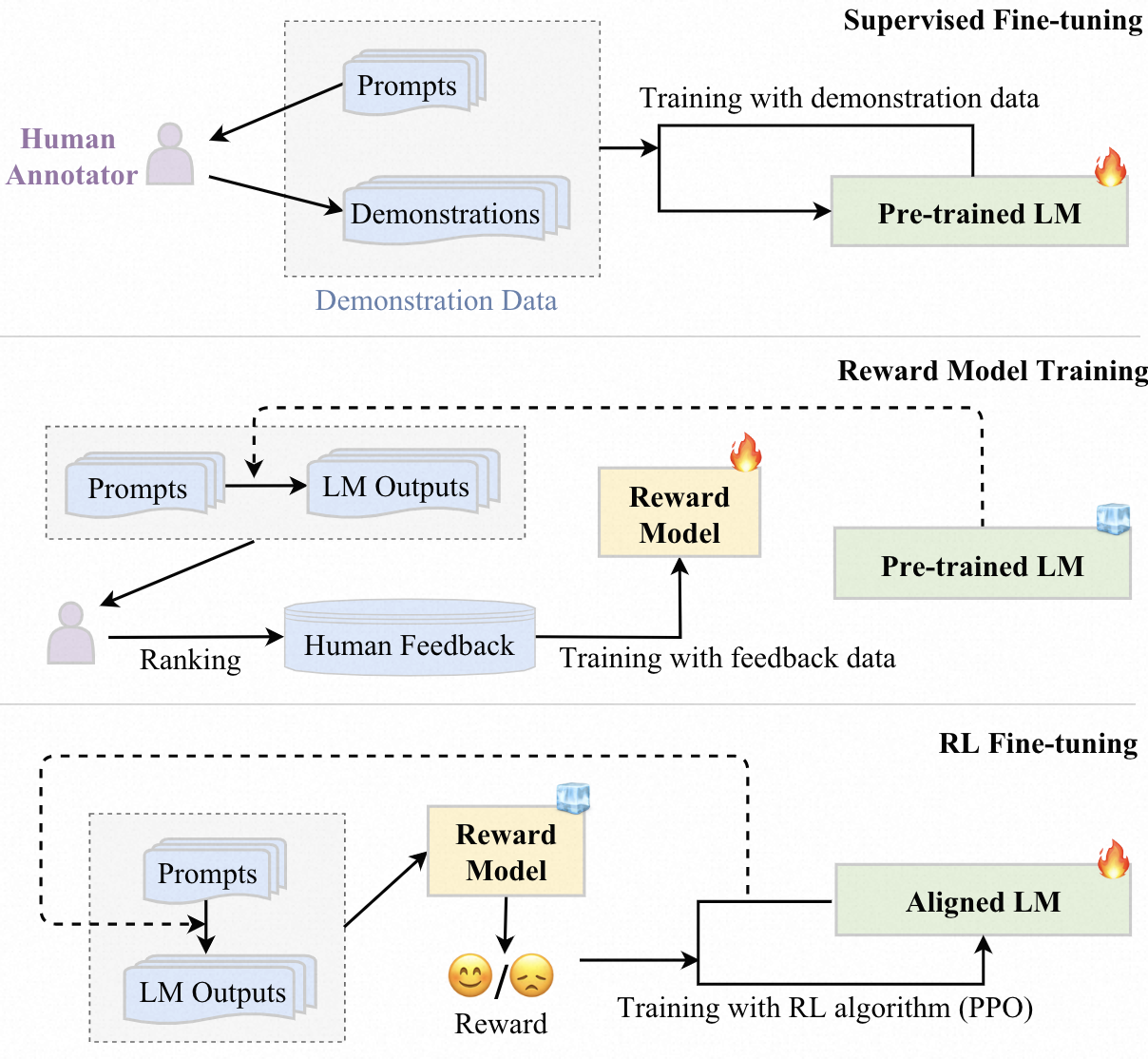
- 监督训练(可选):收集人类标注的训练数据来fine-tune语言模型,使其能够产生人类期望的输出
- 训练reward model:使用人类反馈数据训练reward model,收集LM产生输出,然后让人类打标员对结果进行打标,通过监督训练使模型可以预测人类的喜好。如InstructGPT训练一个6B模型来对输出进行排序
- RL finetune:
- LM作为policy,action space为整个字典空间,reward为reward model给出,state为当前产生的句子
- 根据PPO的公式,会有一个正则项(惩罚项),通常使用KL散度来约束当前的LM和最初的LM,使其不能离的太远
- 通过最大化reward的期望,使LM模型的输出能够更加贴近人类的期望
应用
使用功能大模型的方式为设计解决各种task的任务描述,主要包括两种形式:
- in-context learning:将任务用自然语言进行描述
- chain-of-thought prompting:可以在语言描述中加入中间的推理步骤,来加强in-context learning

In Context Learning
prompt的格式:
prompt可以按照下列步骤生成:
- 先输入问题的描述
- 然后选择少量的示例,按照一定的次序排列
- 将test instance加在最后,让LLM输入答案
即格式可以表示成:$\text{LLM}(I, f(x_1, y_1), …, f(x_k, y_{k+1}), f(x_{k+1}, _)) \rightarrow \hat{y}_{k+1}$。ICL非常依赖prompt的设计,本文主要关注demonstration的设计,以及ICL内在运行机制两部分
demonstration design
主要包括三个部分
- demonstration的选择:
- 使用的例子不同,ICL的表现有很大不同,因此需要选择合适的例子
- 通过heuristic方法(kNN等)选择与任务最相关的例子,或者通过LLM来根据添加例子后得到的性能提升进行选择
- demonstration的格式:
- 可以通过将例子的QA填入固定模板、将其分解为多个步骤(CoT)、将其拆解为多个子问题来形成prompt
- demonstration的次序:
- LLM有时会出现重复末尾样例的作为答案的情况,因此需要给样例安排合适的顺序
- 可以通过heuristic方法如根据和query的embedding的距离进行排序(越近越靠后)、根据entropy等,也可以让LLM进行排序
内在机制
- 预训练如何影响ICL
- 预训练任务的设计对LLM的ICL能力有较大的影响,ICL更依赖于预训练语料的来源而非数量,当训练语料能被聚类成多个不常出现的簇而非均匀分布时,就会显现ICL能力
- LLM在inference阶段如何实现ICL
- 主要从梯度下降以及ICL为隐式的finetune方面进行考虑
- 通过前向计算,LLM能够计算样例的元梯度,并通过attention机制进行隐式的梯度下降 -> LLM的head的某些注意力头能够执行与 ICL 能力密切相关的任务无关的原子操作(例如复制和前缀匹配)
- 在预训练阶段大语言模型在参数中隐式地编码了一个模型,通过 ICL 中提供的示例,大语言模型可以实现诸如梯度下降之类的学习算法
- 主要从梯度下降以及ICL为隐式的finetune方面进行考虑
Chain-of-Thought
在复杂的reasoning任务上,可以通过在ICL的prompt中加入中间步骤来提高LLM的表现
in-context learning with CoT
Few-shot CoT:: 将输入由$<input, output>$改为$<input, CoT, output>$,主要关注一下两点:
- CoT prompt design:CoT的多样性(每个CoT问题可以有多种路径)可以提高模型的表现->更复杂的reasoning路径能够更好的激发LLM的reason能力;Few-shot CoT需要使用人为标注的CoT样例,可以视为一种特殊的ICL,但是CoT对于样例的排序不敏感
- Enhanced CoT Design:现有的研究主要集中在如何生成多个CoT路径,并从中找到共识。如self-consistency会生成多种路径,并在路径中进行采样(采用beam serach而非每个步骤进行Greedy search)。研究表明reason path的多样性是CoT Reasoning带来性能提升的关键
Zero-shot CoT: 不需要人工标注,通过prompt的设计让LLM产生中间步骤,并使用产生的步骤作为CoT来产生最终答案。如通过”Let’s think step by step”来产生中间的Reasoning,通过”Therefor, the answer is”来产生答案。->只有当模型尺寸足够大时才会有这种能力
关于CoT的进一步讨论
CoT什么时候有用:
只有当模型足够大,且所在的任务需要逐步的推理时(数学/常识/符号 Reasoning),才会有用。在普通任务上甚至会降低表现
CoT是如何工作的
- 能力来源:
- 一种说法是由于在代码语料上的预训练使LLM具有推理能力(代码组织良好,有逻辑,有流程),但没有消融实验可以证明
- Instruction tuning与CoT的关系不大,在CoT数据集行进行Instruction tuning也不会提高模型性能
- prompt中各成分的作用:
- CoT和ICL的不同主要在于reasoning可以视为最后结果的先验,因此可以看reasoning的到的中间过程哪些更重要将prompt拆分成符号、范式、文本三部分,后两者更重要,且二者存在共生关系:文本帮助大模型产生有用的范式,范式帮助LLM理解任务并产生文本解决问题
利用CoT可以使大模型解决多模态问题,并让LLM在某个领域表现更好
能力评测
包括3种通用评测任务和多种高级评测任务
基础评测任务
主要包括以下三种
language generation
可以分为下列三种
- Language modeling:最基础的能力,即根据前面的文本预测下一个token,通常使用zero-shot设定下的perplexity指标衡量模型能力,LLM大幅超越以往的模型,且越大的模型准确率越高,perplexity越低
- Condition Text Generation:给定条件,产生满足特定任务需求的文本,如翻译、总结、问答等。指标包括自动评测以及人工投票,给出少量example,LLM即可超越全量finetune的PLM
- Code Synthesis:产生程序代码,使用pass rate作为评测指标,LLM甚至可以超过部分人类
问题:
- Controllable generation:当对生成的文本有负载的结构约束时,LLM可以很好地处理局部关系(如段落内的文本),但很难处理全局关系(如全文各段的关系)。一种解决办法是将单步的生成拆分成多个步骤的迭代,即CoT的思想;另一个问题为文本的安全性,LLM会生成带有偏见或冒犯性的语言,可以通过RLHF控制,但依赖于人工标注,且没有一个优化目标
- Specialized generation:特定化生成需要专业的领域知识,这些很难融入大模型。如果LLM在某些领域非常专业,那么在其他领域效果可能就不好->灾难性遗忘,alignment tax等
Knowledge Utilization
基于支撑性的事实数据,完成知识密集的任务,是LLM的一项重要能力。要求LLM能从预训练预料中得到丰富的知识,或者可以利用外部数据,主要分为一下三种
- 闭卷QA: 检测LLM从预训练语料中学到的知识,不能使用外部数据。使用的指标为accuracy,模型越大,训练数据越多,与测评任务相关的数据越多,LLM的表现越好 ->可以用于检测LLM从预训练语料中学到的知识好坏
- 开卷QA: 可以检索外部知识或文件,常与文本搜索器或搜索引擎搭配使用。使用的指标为accuracy或者F1-Score。现有的研究主要关注LLM如何使用提取到的知识回答问题,在外部数据的加持下,小模型可以比10倍参数量的闭卷大模型表现更好 -> 还可以检查知识的时效性
- knowledge Completion: 预测或填充知识单元中缺失的部分 -> 可以检查LLM学到多少以及学到了哪种知识。
主要问题:
- Hallucination:模型产生的文本和现有的知识有冲突,也不能被验证是否正确。幻觉在现有的LLM中经常出现,表明LLM还很难精确的控制内部或外部知识的使用。-> alignment tuning能一定程度上减缓,即通过高质量的数据和人类标注
- 知识的时效性:LLM很难解决使用最新知识才能解决的问题,可行的路径包括定期finetune(开销太高且可能导致灾难性遗忘问题),因此需要研发一种将新知识融入现有LLM的有效且高效的办法 -> chatgpt使用plugin方式,将相关知识放入context中来利用新知识
Complex Reasoning
理解并利用复杂的事实,从而得到最终结果或者做出决定的推理能力,主要包括以下三种
- Knowledge Reasoning:基于逻辑关系和事实回答问题,一般是用各种QA数据集,指标为结果的accuracy以及过程的质量(自动指标或人工评估)。一般会采用CoT的方式进行多步的评估,会带来问题:中间某个步骤错了导致最终结果出错->可以通过对beam search或者ensemble来进行缓解
- Symbolic Reasoning:-
- Mathematics Reasoning:理解数学符号、逻辑及计算来解题或者进行定理证明。解数学题可以使用CoT提高LLM的性能,另外在大量数学相关的语料上进行预训练也可以提高性能;自动定理证明需要推理模型严格遵循推理逻辑和数学技能,证明成功率是评估指标。现有的 ATP 工作利用大语言模型来辅助定理证明器进行证明搜索 -> 一个问题是缺乏语料,可以通过将非正式声明转化为正式的语言来扩充语料,并通过生成草稿减少搜索空间
主要问题:
- 非一致性:可能沿着正确的推理路径得到错误的结果,或沿着错误的路径得到正确的结果 -> 借助外部工具或者每个步骤检查的机制进行缓解:另外还存在问题稍微变化,得出的推理路径就会发生变化的问题。-> 通过求解路径的ensemble来解决
- 数值计算问题:进行数值计算时很难,尤其是没见过的符号 -> 一种方法是增加训练数据,另一种方法是通过插件,如chatgpt引入计算器(需要LLM具有tool manipulation能力)
高级能力及测评
Human Alignment
测试模型按照人类喜好生成答案的能力,可以从helpfulness,honesty,safety方面进行评测,前两个可以用自动的指标进行评测。除了自动评测,人工评价是一种更好的方式。一些研究提出使用具体指令和设计标注规则来指导评价,可以大大提高大语言模型 的人类对齐能力,此外,高质量的预训练数据可以减少对齐 所需的工作量
Interaction with External Environment
LLM具有从外部获得反馈并根据指示进行action的能力,该能力也具有涌现的特性,仅在大规模的模型上能产生有意义的plan, 测评的指标包括指令的正确性和可执行性,或者成功率
Tool Manipulation
LLM可以根据需要调用外部的工具(包装成API形式),让LLM具有除了语言模型以外的其他能力 -> 通过在context中加入examplar或者在工具使用的仿真数据集上进行finetune,从而使LLM获得使用tools的能力
上述三种能力可以给LLM的实际使用带来很大价值:符合人类的偏好,在实际场景中正确行动,扩展能力范围
公开benchmark和能力分析
公开benchmark
- MMLU:涵盖从基础到高级能力测评,能体现模型的scaling law
- BIG-bench:包含204种任务,还有简化版本BIG-bench-Lite(24种任务)以及更难的版本Big-bench-hard
- HELM:16个场景和7类metric,在这个数据集上可以看出Instruction tuning可以提升LLM的性能
LLM能力的分析
通用能力
- 熟练度:测评模型熟练度时,会采集部分数据,然后在few-shot/zero-shot的设定下测试LLM的性能,实验结果显示大语言模型对通用任务有着卓越的解决能力,如GPT-4等,但也有限制,如GPT-4不能辨别自己产生的结果和训练数据之间的一致性;在需要plan的任务上表现不好;对不熟悉的概念会产生误解等
- 鲁棒性:观察随着输入的改变,模型输出改变的程度。大模型的鲁棒性比小模型的鲁棒性要好,但也存在鲁棒性不稳定和对prompt敏感的问题
专业能力:
- 医学:能够处理一系列健康相关的问题,通过考试等,但是会存在错误解释医学名词以及隐私等问题
- 教育:可以通过部分考试并作为读写助手,但是面临滥用问题
- 法律:有法律条文解释和推理能力,但也存在个人隐私或版权问题等
LLM还有一定的自我意识、心理理论等能力,在心理理论能力方面,约等于一个9岁儿童
总结
- LLM能力来源于巨大的模型尺寸(scaling law),但涌现能力机制未知
- 模型结构为Transformer,需要解决灾难性遗忘等问题
- 需要发展系统、经济的模型训练方法,来持续的进行LLM的pretrain/finetune
- pretrain/finetune非常昂贵,prompting为使用LLM的最好方法。但是也存在问题:
- 依赖人工来设计不同的prompt
- 专业的任务需要专业的知识
- 现在形式基本为单轮,需要研究交互式的promting机制
- 面临安全挑战,如知识幻觉等。可以通过RLHF来缓解,但其依赖高质量的专业数据标注,需要降低标注成本