Nougat: Neural Optical Understanding for Academic DocumentsA Survey of Large Language Models
前言
本文主要贡献包括:
- 开源了一个可以将PDF转换为轻量标记语言的预训练模型
- 提出了一个可以将PDF和源代码进行配对,从而创建数据集的Pipeline
- 该方法仅依靠PDF的图像,因此也适用于扫描版的论文和书籍
框架
算法使用的模型结构为Encoder-Decoder架构的transformer,因此可以进行End-to-End的训练和预测,输入图像,输出文本。
模型

Encoder: 作者使用Swin Transformer作为模型的Encoder,该结构将图像分成多个不重叠的Patch,经过多层self-attention layer的堆叠,将多个windows内部的信息进行聚合,得到一系列Patch提取出的Embedding
Decoder: 作者使用mBard作为Decoder,输入为编码好的图像,然后通过自回归方式输出tokens,最终投影为输出单词的logit
参数配置
Encoder输入尺寸为$896 \times 672$,Decoder输出的最大序列长度为$S=4096$,共有10层,总参数量大小为350M
训练过程中使用AdamW优化器,总共训练3个epoch,batch size为192,初始lr为$5 \cdot 10^{-5}$,最终lr为$7.5 \cdot 10 ^{-6}$
数据增强

作者使用的训练数据为电子版pdf,由于最终需要识别扫描版pdf,因此需要对电子版pdf的图像进行数据增强,包括膨胀、腐蚀、高斯噪声等
此外,在训练过程中还对GT中的文本进行随机扰动,可以防止文本输出的循环
数据集
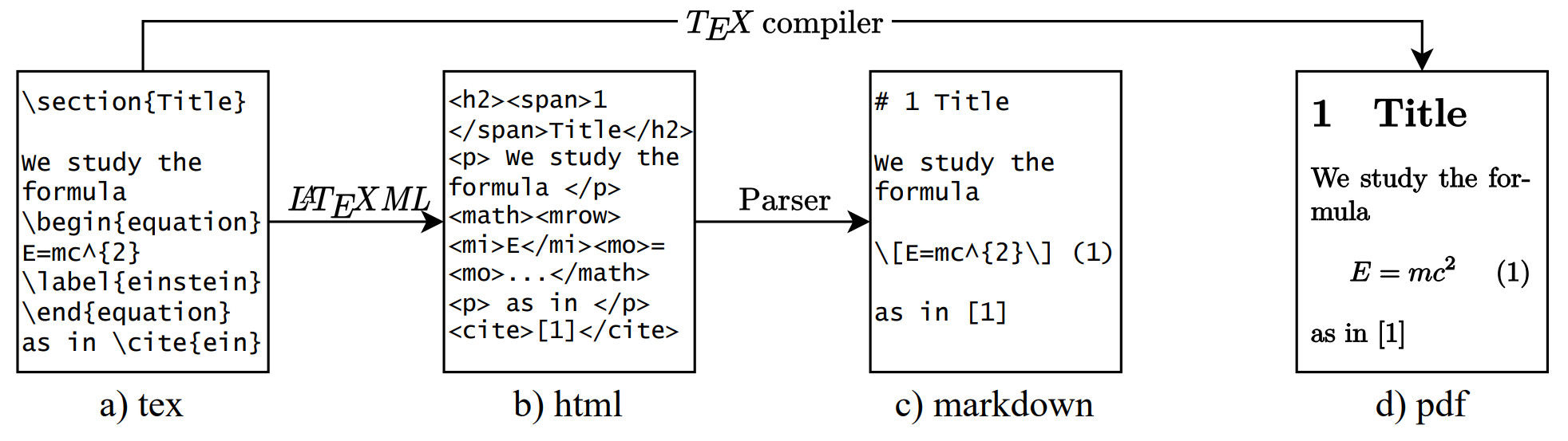
目前没有PDF/源代码配对的数据集,作者使用arxiv/PubMed Central/Industry Documents Library中的数据创建了数据集
Arxiv: 从tex -> html -> markdown进行转换,从而得到PDF与轻量级标记语言对应的数据
PMC: 处理流程与Arxiv类型,对数据集提供的额外的XML数据也做同样处理
IDL: 仅有PDF和对应的OCR文本识别信息,没有格式信息,所以仅用于预训练
分页
PDF的分页是由编译器控制,而markdown的获得并不通过编译器,因此需要通过将PDF每页的文本和markdown中的文本进行匹配得到分页信息。对于图表,PDF中的位置和源码中的位置可能不同,为了解决这个问题,作者在预处理阶段使用pdffigures2删除这些元素。然后,使用识别到的图例与XML文件中的图例进行比较,并根据Levenshtein距离进行匹配。在完成文档分割后,再将删除的图例和表格将被插入到每一页
词袋匹配
为了能将Latex源码分段及分页,作者训练了一个词袋模型,在完成页码的预测后,由于可能存在错误,作者使用了决策树来辅助分页
模糊匹配
在大致的分割后,需要进一步确认精确的分割点,作者将预测的分割点附近的源码文本,与PDF识别文本中的前一页的最后一句、后一页的第一句进行模糊匹配,如果能够匹配上,则证明预测的分割点正确。否则,寻找匹配距离最小的分割点
由于数据集为LaTeXML处理得到,因此可能存在多种错误或缺失,但是大量的训练样本可以补偿这些小错误。
实验
结果对比
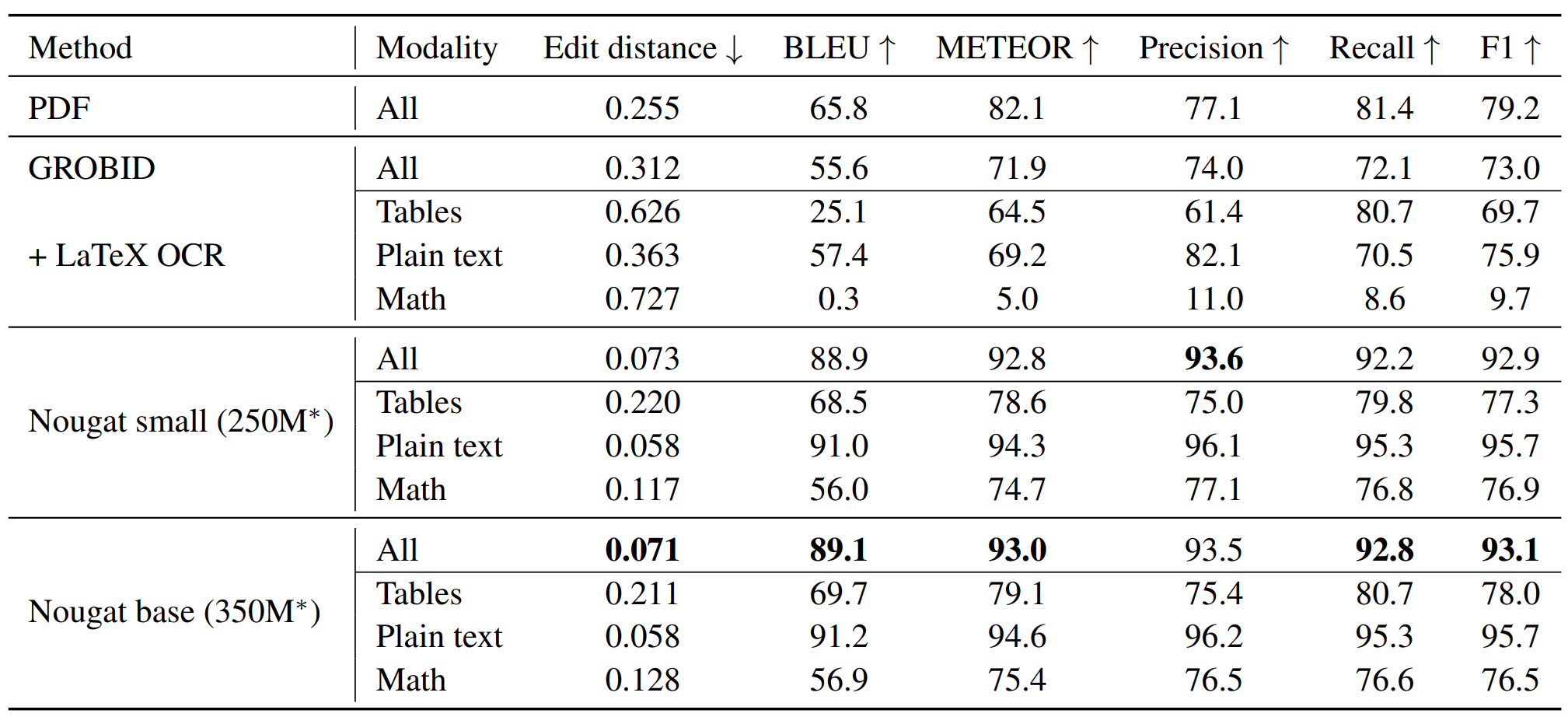
作者使用了Edit Distance/BLEU/METEOR/F-measure等多种指标对比了不同的算法,并考虑了不同的模态,如文本/公式/图表,在这里,由于同一个公式可以使用多种Latex代码表示,因此该模态的指标会低于纯文本。总体来看,Nougat的大模型和小模型在所有指标上都取得了最好的指标,且大模型和小模型的指标相当
循环输出问题
针对模型推理时产生的输出文本重复问题,作者在两个方面进行缓解
数据增广: 在训练时引入文本的随机扰动,让模型学会如何处理错误预测的token
循环检测: 在输出文本时,对于输出文本的某个位置,向前计算长度为15的窗口内的logits方差,作为一个指标,然后在向后的文本窗口内计算这个指标的方差,根据阈值来判断是否产生循环
不足
能力: 会产生循环问题,以及在非拉丁文的文本上表现不好
生成速度: 生成速度较慢,在A10上生成1400 token耗时约为19.5s
总结
本文提出了一个端到端训练的Encoder-Decoder架构的transformer,用于将文件转换为轻量化的标记语言,该方法仅依赖图像;此外,本文还提出了一个自动化、非监督的数据生产流程,用于产生数据,帮助模型训练。